ChatGPT做推荐怎样样?阿里巴巴最新《ChatGPT作为通用推荐模型性能》评估,表现良好,有其局限,大有潜力
阿里最新ChatGPT在推荐任务上的表现评估,值得关注!
chatgpt中文版 http://chatgpt.guige.xyz

在过去的几十年中,推荐系统获得了长足的进步,得到了广泛的利用。但是,传统的推荐方法大多是针对特定任务的,缺少有效的泛化能力。最近,ChatGPT的出现通过增强会话模型的能力,大大推动了NLP任务。但是,ChatGPT在推荐领域的利用还没有被深入研究。该文彩用ChatGPT作为通用推荐模型,探索其将大范围语料库中获得的大量语言和世界知识迁移到推荐场景的潜力。具体地,我们设计了一套提示集,并在评分预测、序列推荐、直接推荐、解释生成和评论摘要5种推荐场景下对ChatGPT的性能进行了评估。与传统推荐方法区别,在全部评估进程中没有对ChatGPT进行微调,仅依托提示本身将推荐任务转换为自然语言任务。进一步,探讨了使用少样本提示注入包括用户潜伏兴趣的交互信息,以帮助ChatGPT更好地了解用户需求和兴趣。在Amazon Beauty数据集上的综合实验结果表明,ChatGPT在某些任务上获得了较好的效果,在其他任务上能够到达基线水平。在两个面向可解释性的任务上进行了人工评估,以更准确地评估区别模型生成的内容的质量。人工评测表明ChatGPT能够真正理解所提供的信息,并生成更清晰、更公道的结果。希望该研究能够启发研究人员进一步发掘ChatGPT等语言模型提高推荐性能的潜力,为推动推荐系统领域的发展做出贡献。
https://www.zhuanzhi.ai/paper/c1a5e954689aace228e596f676da195e
1. 援用
作为解决信息过载和增强用户体验的关键技术,推荐系统在过去的十年中获得了长足的进步,被广泛利用于各种web利用中,如产品推荐[32,49,51,59]、视频推荐[39,54,66]、新闻推荐[55⑸7]、音乐推荐[27,47]等。同时,随着深度学习的发展,推荐系统也经历了多个阶段。在初期,基于协同过滤的方法[5,6,44,62]主要用于从用户-项目交互中对用户的行动模式进行建模。后来,随着用户和项目边信息被引入推荐系统,基于内容的推荐[36,37,40,53,58]和基于知识的推荐[2,8,16,18]因其能够提供个性化推荐而遭到关注。
但是,大多数传统的推荐方法都是针对特定任务的。因此,针对区别的任务或利用场景,需要特定的数据来训练特定的模型,缺少高效的泛化能力。为了解决这个问题,研究人员将重点转移到在推荐场景中实现预训练语言模型(PLMs),由于PLMs表现出了使人印象深入的适应性,可以显著提高低游NLP任务的性能。为了有效地将用户交互数据转换为文本序列,设计了各种提示[64]来将用户交互数据转换为文本序列。P5[19]和M6-Rec[11]侧重于构建基础模型,以支持广泛的推荐任务。
最近,ChatGPT的出现通过增强对话模型的能力,大大推动了NLP任务,使其成为企业和组织的有价值的工具。Chataug等[12]利用ChatGPT来重新表达句子以实现文本数据增强。Jiao等,[23]发现ChatGPT在高资源语言和低资源语言上的翻译能力都与商业翻译产品具有竞争力。Bang等人[3]发现ChatGPT在情感分析任务中比之前最早进的零样本模型有很大的优势。但是,ChatGPT在推荐领域的利用还没有深入研究,ChatGPT会不会能在经典推荐任务上表现良好依然是一个开放的问题。因此,有必要建立一个基准对ChatGPT与传统推荐模型进行初步评估和比较,从而为进一步探索大范围语言模型在推荐系统中的潜力提供有价值的见解。
为了弥补这一研究空白,直接将ChatGPT作为一个可以处理各种推荐任务的通用推荐模型,尝摸索索从大范围语料库中获得的广泛的语言和世界知识会不会可以有效地迁移到推荐场景中。我们的主要贡献是构建了一个基准来跟踪ChatGPT在推荐场景中的表现,并对其优势和局限性进行了全面的分析和讨论。具体地,设计了一套提示集,并在评分预测、顺序推荐、直接推荐、解释生成和评论摘要5个推荐任务上评估了ChatGPT的性能。与传统推荐方法区别,在全部评估进程中没有对ChatGPT进行微调,仅依托提示本身将推荐任务转换为自然语言任务。另外,还探索了使用少样本提示注入包括用户潜伏兴趣的交互信息,以帮助ChatGPT更好地了解用户需求和偏好。
在Amazon Beauty数据集上的综合实验结果表明,从准确率的角度来看,ChatGPT在评分预测方面表现良好,但在序列推荐和直接推荐任务中表现较差,在某些指标上仅到达与初期基线方法相近的性能水平。另外一方面,虽然ChatGPT在解释生成和评论摘要等可解释推荐任务的客观评价指标方面表现不佳,但额外的人工评估表明,ChatGPT优于最早进的方法。这突出了使用客观评价方法来准确反应ChatGPT真实可解释推荐能力的局限性。另外,虽然ChatGPT在基于准确率的推荐任务中表现不尽如人意,但值得注意的是,ChatGPT并没有在任何推荐数据上进行专门的训练。因此,通过纳入更多相关的训练数据和技术,在未来的研究中仍有很大的改进潜力。相信该基准不但揭露了ChatGPT的推荐能力,而且为研究人员更好地了解ChatGPT在推荐任务中的优势和不足提供了一个有价值的出发点。另外,我们希望该研究能够启发研究人员设计新的方法,利用语言模型(如ChatGPT)的优势来提高推荐性能,为推荐系统领域的发展做出贡献。
2.ChatGPT 推荐
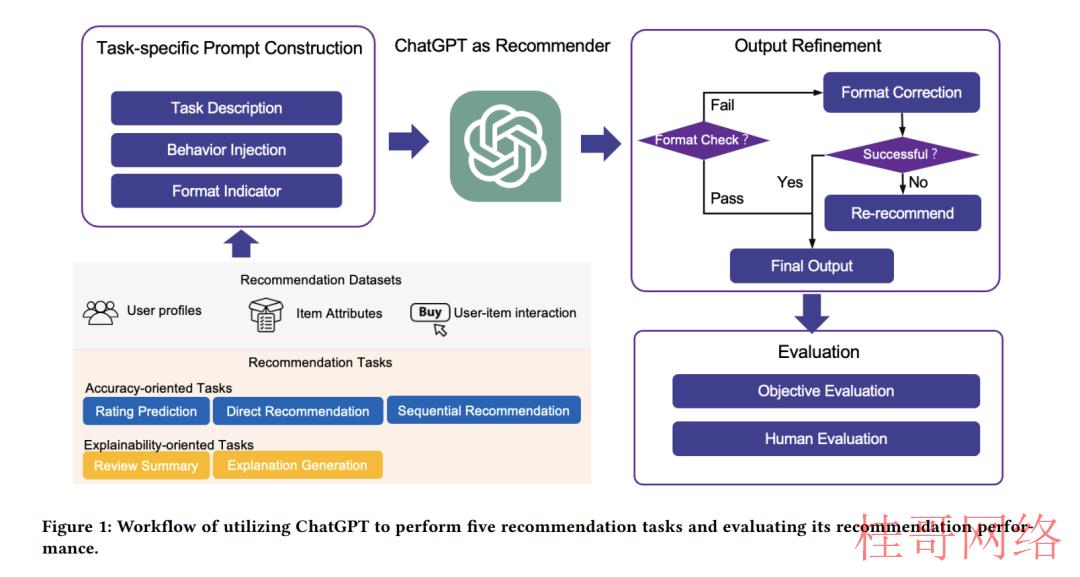
使用ChatGPT完成推荐任务的工作流程如图1所示,包括三个步骤。首先,根据推荐任务的具体特点构建区别的提示(第2.1节);其次,将这些提示信息作为ChatGPT的输入,根据提示信息中指定的需求生成推荐结果;最后,通过细化模块对ChatGPT的输出进行检查和细化,细化后的结果作为终究的推荐结果返回给用户(章节2.2)。
2.1 针对任务的提示构建
本节研究ChatGPT的推荐能力,设计针对区别任务的提示。每一个提示由三个部份组成:任务描写、行动注入和格式唆使符。利用任务描写使推荐任务适应自然语言处理任务。行动注入旨在评估少样本提示的影响,其中融入了用户-物品交互,以帮助ChatGPT更有效地捕捉用户偏好和需求。格式指标用于束缚输出格式,使推荐结果更容易于理解和评估。
2.1.1评分预测。评分预测是推荐系统中的一项关键任务,旨在预测用户对特定物品的评分。这项任务对为用户个性化推荐和改良整体用户体验相当重要。最近几年来,深度学习模型[20]和矩阵分解技术[26]的使用,有效地解决了推荐系统中的稀疏性问题。与LLM的创新推荐范式一致,我们在评分任务上进行了实验,触及制定两种独特的提示类型以引出结果。我们在图2中提供了一些示例提示。
2.1.2 序列推荐。序列推荐是推荐系统的一个子领域,旨在根据用户过去的顺序行动预测用户的下一个项目或行动。由于其在电子商务、在线广告、音乐推荐等领域的潜伏利用,最近几年来遭到了愈来愈多的关注。在序列推荐中,研究人员提出了各种方法,包括循环神经网络[31]、对照学习[68]和基于注意力的模型[52],以捕获用户-物品交互中的时间依赖和模式。为顺序推荐任务族设计了三种区别的提示格式。这包括:1)根据用户的交互历史直接预测用户的下一个项目,2)从候选列表当选择一个可能的下一个项目,其中只有一个项目是积极的,并基于用户的交互历史,3)使用用户之前的交互历史作为基础,预测特定项目会不会会是用户的下一个交互项目。这些提示格式旨在提高顺序推荐的准确性和有效性,并以严格的学术原则为基础。这些提示的例子可以在图2中看到。

图2: Beauty数据集上基于准确性的任务提示示例。黑色文本表示任务描写,红色文本表示格式要求,蓝色文本表示用户历史信息或少次信息,灰色文本表示当前输入。
2.1.3 直接推荐。直接推荐,也称为显式反馈推荐或基于评分的推荐,是一类依赖用户评分或评论情势的显式反馈的推荐系统。与其他依赖隐式反馈(如用户行动或租赁历史)的推荐系统区别,直接推荐系统通过斟酌用户的显式偏好,能够提供更加个性化和准确的推荐。对这项任务,开发了项目选择提示,从潜伏候选人列表当选择最适合的项目。这些提示格式基于严格的学术原则,旨在优化推荐的准确性和相关性。这些提示的例子可以在图2中看到。
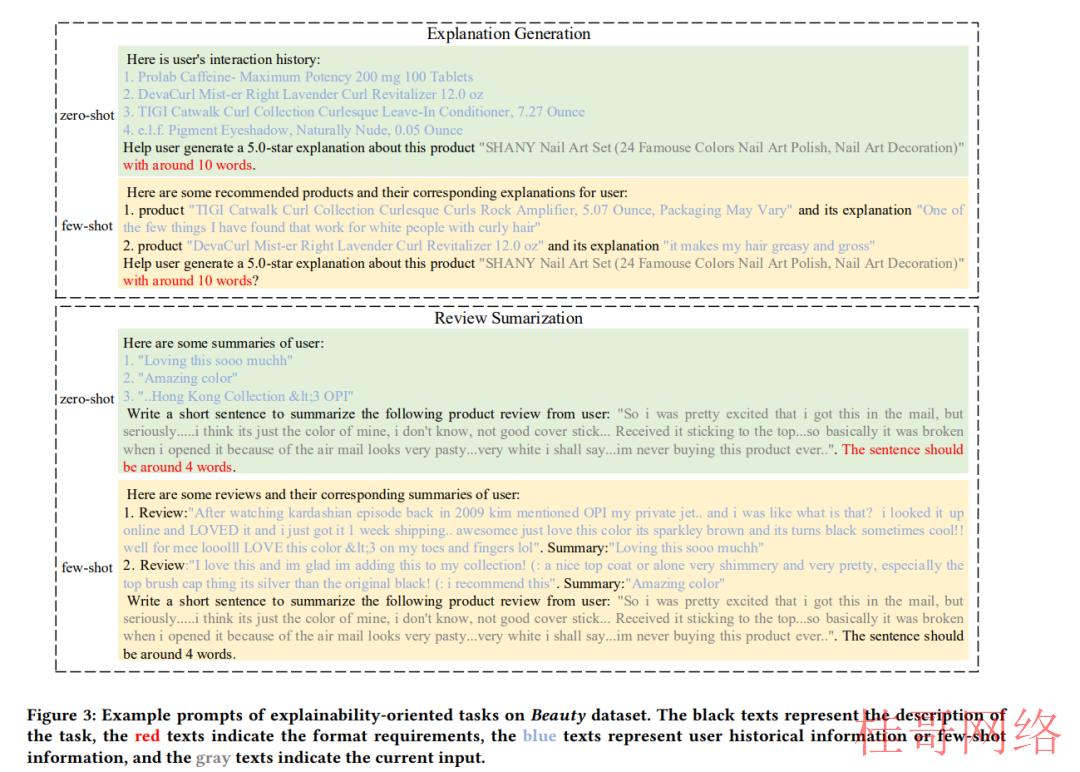
2.1.4 解释的生成。解释生成是指为用户或系统设计人员提供解释,以阐明为何推荐这些项目。从而提高了推荐系统的透明性、说服力、有效性、可信性和用户满意度。另外,该模型便于系统设计人员对推荐算法进行诊断、调试和优化。ChatGPT等大型语言模型可以利用其包括的大量知识,通过用户的历史交互记录来了解用户的兴趣,并为用户的行动提供公道的解释。具体来讲,我们要求ChatGPT模型生成文本解释,以证明用户对所选物品的偏好,如图3所示。对每一个种别,可以包括额外的辅助信息,如提示词和星级评级。
2.1.5 Review总结。随着人们对简洁、易于理解的内容的需求不断增长,自动生成摘要在自然语言处理中变得愈来愈重要。与解释生成任务类似,我们创建了两种类型的提示:零样本提示/少样本提示,并在图3中提供了一些示例提示。
3.2 输出Refinement
为了保证生成结果的多样性,ChatGPT在其响应生成进程中加入了一定程度的随机性,这可能会致使对相同的输入产生区别的响应。但是,在使用ChatGPT进行推荐时,这类随机性有时会给评估推荐项目带来困难。虽然prompt构造中的格式唆使器可以在一定程度上减缓这个问题,但在实际使用中,它依然不能保证预期的输出格式。因此,我们设计了输出细化模块来检测ChatGPT的输出格式。如果输出通过格式检查,则直接将其作为终究输出。如果没有,则根据预定义的规则进行修改。如果格式校订成功,则将校订后的结果用作终究输出。如果没有,则将相应的提示输入ChatGPT进行重新推荐,直到满足格式要求。值得注意的是,在评估ChatGPT时,区别的任务对输出格式有区别的要求。例如,对评分预测,只需要一个特定的分数,而对顺序推荐或直接推荐,则需要一个推荐项目的列表。特别是对序列推荐,一次性将数据集中的所有项目提供给ChatGPT是一个挑战。因此,ChatGPT的输出可能与数据集中的项集不匹配。针对这一问题,该文提出了一种基于类似度的文本匹配方法,将ChatGPT的预测结果映照回原始数据集。虽然该方法可能不能很好地反应ChatGPT的能力,但它依然可以间接地展现其在序列推荐中的潜力
3 评价
为了评估ChatGPT,在Amazon真实数据集上进行了广泛的实验。通过与各种代表性方法和消融研究在区别任务上的性能比较,旨在回答以下研究问题:
RQ1:与最早进的基准模型相比,ChatGPT的性能如何?
RQ2:少提示对性能有甚么影响?
RQ3:如何设计人工评价来评估解释生成和摘要任务?
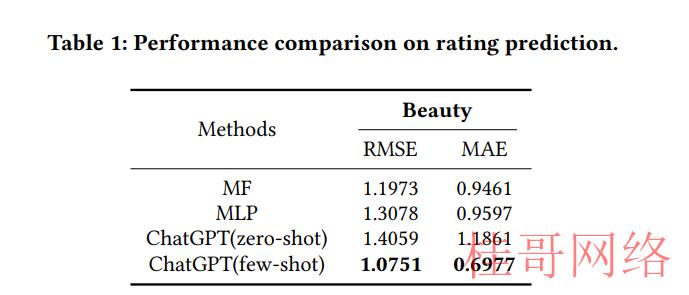
3.3.1 评分预测。为了评估ChatGPT的评分预测性能,采取了零样本和少样本提示,从Beauty数据集上得到的结果总结在表1中。结果表明,对Beauty数据集上看到的种别,少样本提示在MAE和RMSE方面都优于MF和MLP。这些结果为利用条件文本生成框架进行评分预测的可行性提供了证据。
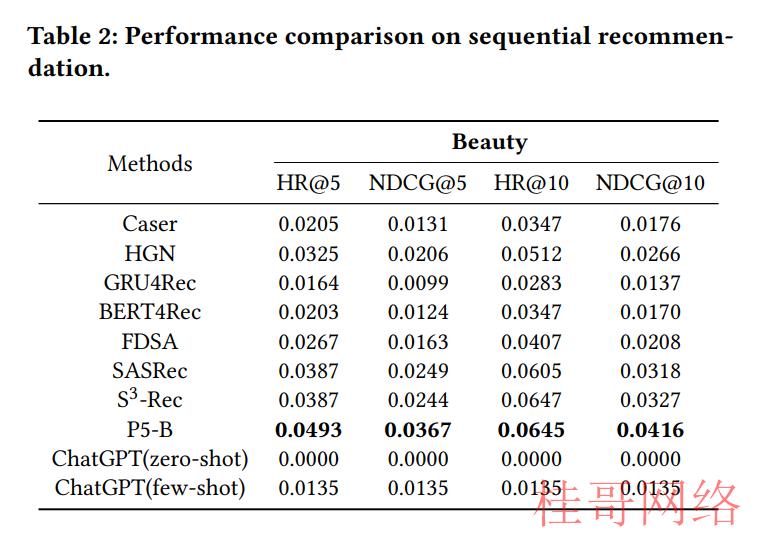
3.3.2 序列推荐。为了评估ChatGPT的序列推荐能力,我们分别进行了零样本和少样本实验,实验结果如表2所示。我们发现,与基线相比,ChatGPT在零样本提示设置中的性能要差很多,所有指标都明显低于基线。但是,在小样本提示设置下,虽然ChatGPT在性能上有了相对的提升,例如NDCG@5超过了GRU4Rec,但在大多数情况下,ChatGPT依然普遍优于经典的序列推荐方法。可能有两个主要缘由致使了这类结果:首先,在提示设计进程中,所有item都由它们的标题表示。虽然该方法可以在一定程度上减缓冷启动问题,但可能致使ChatGPT更关注语义类似性而不是项目之间的迁移关系,而这对有效推荐相当重要。其次,由于提示信息的长度限制,没法将物品集合中的所有物品输入ChatGPT。这致使ChatGPT在预测下一个物品的标题时缺少束缚,致使生成的物品标题在数据集中不存在。虽然可以通过语义类似性匹配将这些预测的标题映照到数据集中现有的标题,但实验表明,这类映照并没有带来显著的增益。因此,对顺序推荐任务,仅仅使用ChatGPT其实不是一个适合的选择。需要进一步探索引入更多的指点和束缚,以帮助ChatGPT准确捕捉历史兴趣,并在有限的范围内做出公道的推荐。
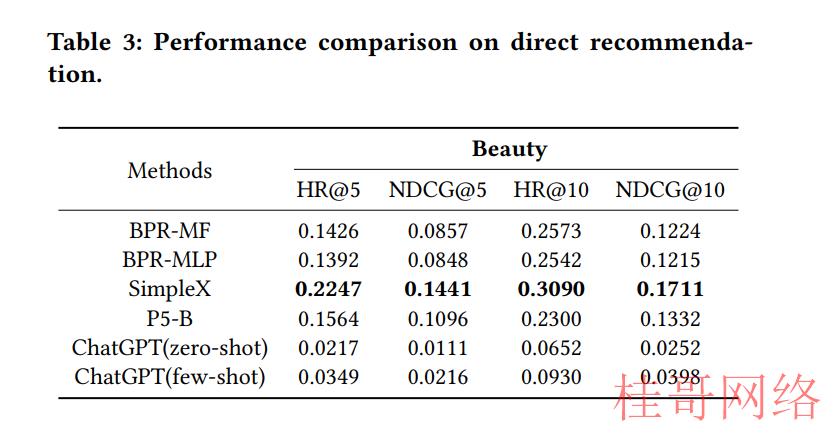
3.3.3直接推荐。表3展现了ChatGPT在直接推荐任务上的性能。与顺序推荐区别,直接推荐要求推荐模型从有限的物品池当选择与用户最相关的物品。我们视察到,在使用零样本提示时,推荐性能明显低于有监督推荐模型。这可以归因于ChatGPT提供的信息不足,致使没法捕捉用户兴趣并生成更随机的推荐。虽然少样本提示可以通过提供用户的一些历史偏好来提高ChatGPT的推荐性能,但依然未能超过基线性能。
结论
该文构建了一个评测ChatGPT在推荐任务中的性能的基准,并与传统的推荐模型进行了比较。实验结果表明,ChatGPT在评分预测上表现良好,但在顺序推荐和直接推荐任务上表现较差,表明还需要进一步探索和改进。虽然有局限性,但ChatGPT在可解释推荐任务的人工评价方面优于最早进的方法,突出了其在生成解释和摘要方面的潜力。该研究对ChatGPT在推荐系统中的优势和局限性提供了有价值的见解,希望能启发未来探索使用大型语言模型来提高推荐性能的研究。展望未来,我们计划研究更好的方法,将用户交互数据纳入大型语言模型,弥合语言和用户兴趣之间的语义鸿沟。
桂}哥}网}络www.gUIgege.cn
TikTok千粉账号购买:https://www.tiktokfensi.com/
本文来源于chatgptplus账号购买平台,转载请注明出处:https://chatgpt.guigege.cn/jiaocheng/29903.html 咨询请加VX:muhuanidc
