从四个角度全面认识 ChatGPT
chatgpt中文版 http://chatgpt.guige.xyz
当下最引人注视的语言模型 ChatGPT 如火如荼,主要或者由于其能力远远超出了传统模型。本文将对 ChatGPT 与传统模型进行对照,深入探讨 ChatGPT 具有的强大能力和其背后的技术来源。另外还将介绍处于大语言模型时期的我们应当如何去做。
◈ 传统语言模型是甚么样的?
那末语言模型究竟是如何学会人类语言机制的呢?当我们向它询问某一个问题时,这个问题就作为了语言模型的输入内容,同理它会去预测下一个单词或字符。每组这样的数据组合都可以称为一个范例,当这样的范例足够多以后,大预言模型就会出现出一个新能力:泛化。也就是说同一个问题,它可以自行拓展,比如说我们问:“床前明月光的下一句是甚么?”模型回答“疑是地上霜”,这是正确答案。那末这时候候如果将问题略微拓展:“床前明月光的后续内容是甚么?”模型也能够理解并处理,这就是所谓的泛化能力。固然这个能力是需要一个长时间的训练进程和大量的数据作为支持的。
过去一直以来的语言模型都是遵守以上机制的,讲的直白一点其实就是一个“文字接龙”机器,你问出的问题它会有对应的答案,即便换个问法可能也是该答案。相信每一个人都体会到过某宝/某多/某东的机器人客服,你问一个问题它是这么回答的,换个问法它或者一样的话术,就说气不气。事实上这样的产品就是传统语言模型的典型代表。
第一 ChatGPT 好像全球的知识它都会,上知天文下知地理,我们可以向它发问各领域的知识,让它帮我们写代码、写稿子等等。
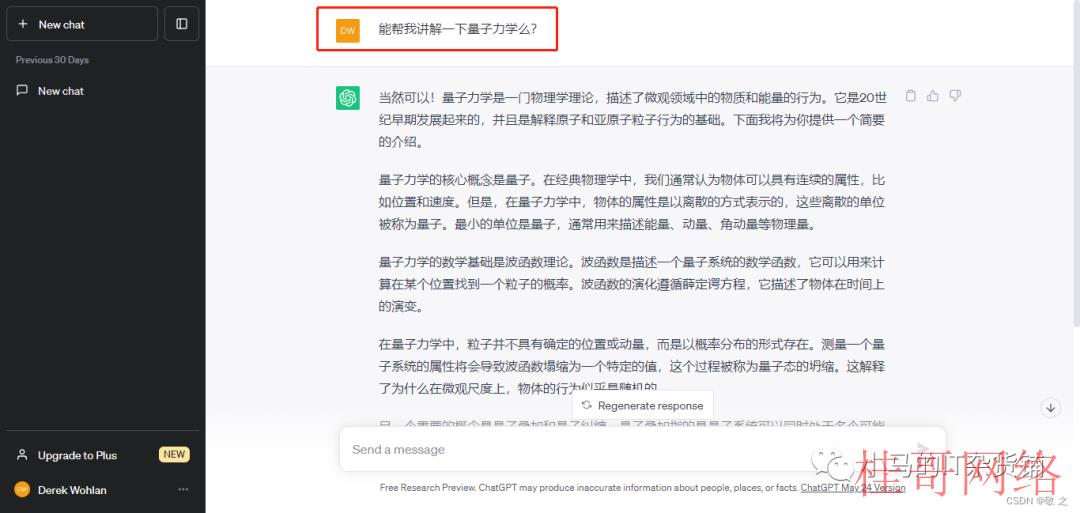
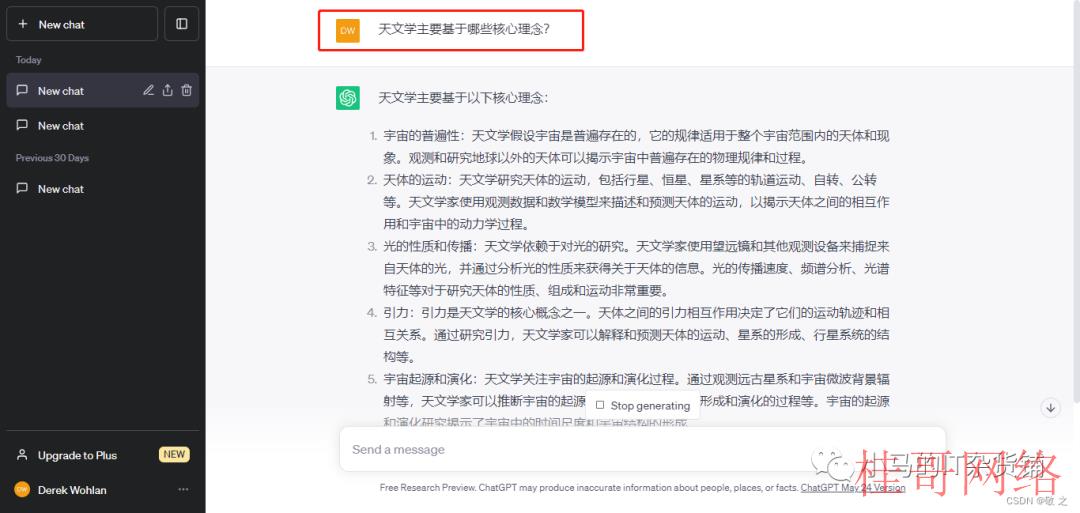
case2:让 ChatGPT 讲授天文学知识
case3:让 ChatGPT 帮我们写一段 python 代码,调用 ChatGPT
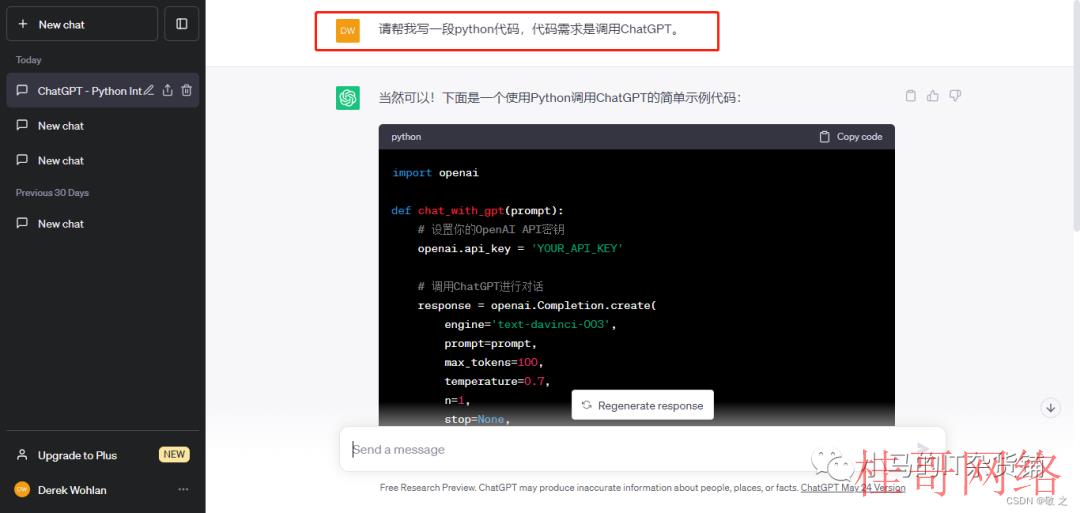
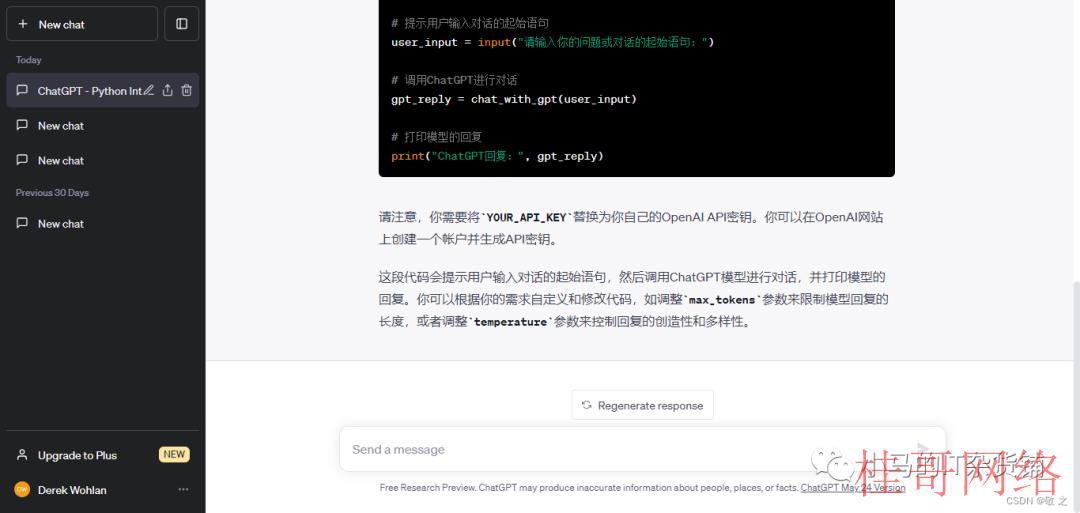
Python 语言调用 ChatGPT 模型代码以下:
import openaidef chat_with_gpt(prompt):# 设置你的OpenAI API密钥= 'YOUR_API_KEY'# 调用ChatGPT进行对话response = openai.Completion.create(engine='text-davinci-003',prompt=prompt,max_tokens=100,temperature=0.7,n=1,stop=None,temperature=0.7,top_p=1,frequency_penalty=0,presence_penalty=0)# 获得模型的回复reply = response.choices[0].text.strip()return reply# 提示用户输入对话的起始语句user_input = input("请输入你的问题或对话的起始语句:")# 调用ChatGPT进行对话gpt_reply = chat_with_gpt(user_input)# 打印模型的回复gpt_reply)
第三 ChatGPT 具有复杂的推理能力,按道理来讲“推理”应当是只有人材能做到的事情,但是现在 ChatGPT 也具有此能力,它也能够根据语义自行推理。
case4:输入一个公考推理题,让 ChatGPT 来解答
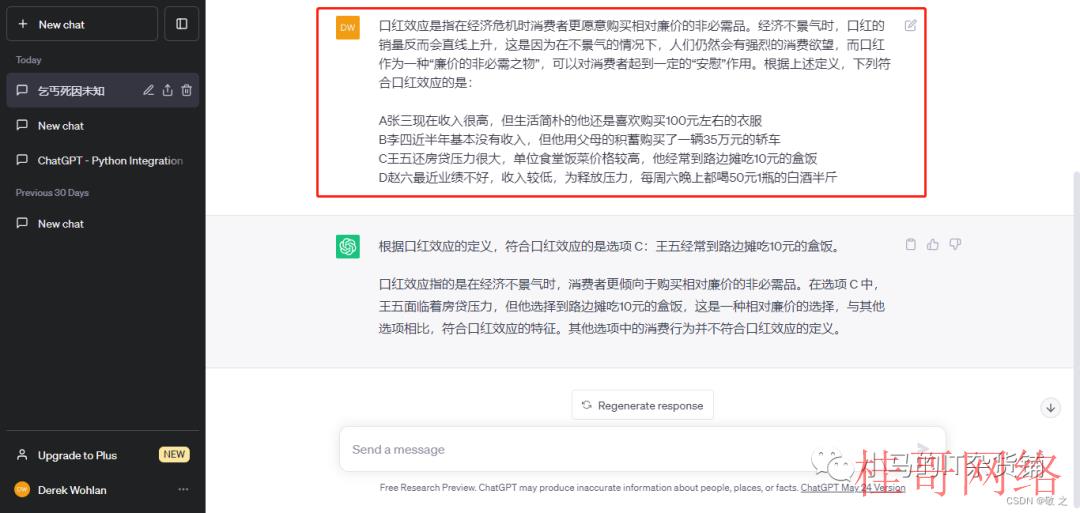
第四 ChatGPT 具有中立、客观、安全的语言表达能力,当我们询问问题时,ChatGPT 的回答常常是准确客观且非常具有条理性的,同时它也会在一些触及不良影响的问题上谢绝回答。
case5:询问当下最具潜力的创业项目
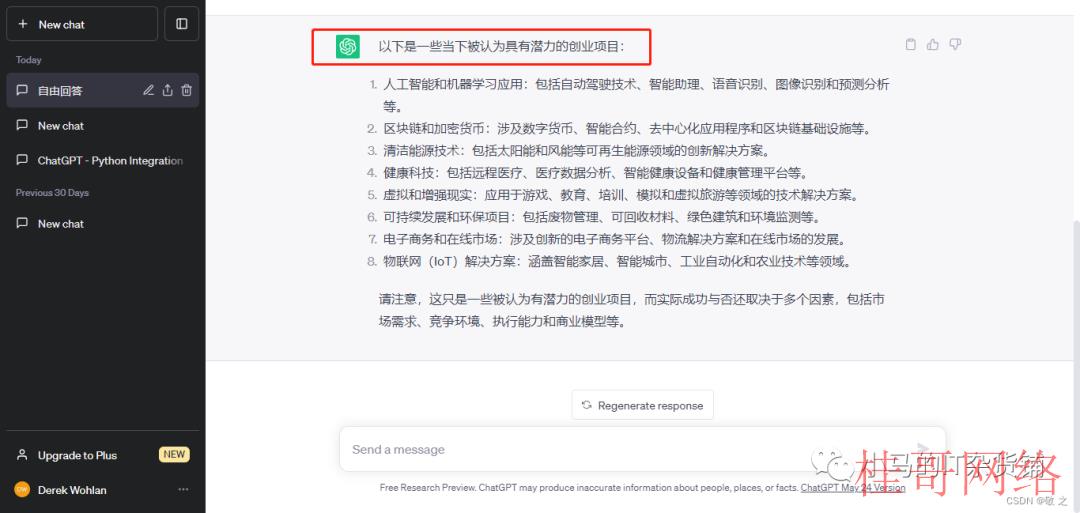
◈这些能力都是怎样做到的?
| OpenAI | 学习资料 | 参数量 |
| GPT1 | 5GB | 1.17亿 |
| GPT2 | 50GB | 15亿 |
| ChatGPT | 45TB+ | 1750亿 |
从始至终语言模型的训练机制都没有变,变的只是模型的量级。俗语说“量变引发质变”,相较于传统语言模型,ChatGPT 便是一个质的改变。
ChatGPT 的复杂推理能力源于“分治思想”,将一个大问题分解为一个个的小问题,逐渐解决。
为语言模型灌输知识和其“分治”的问题处理方式,这也就是我们常说的预训练。但是预训练以后也产生了一个问题:由于预训练接触了太多的数据信息,致使模型的回答没有束缚,甚么都说,不管好的或者不好的!
所以接下来就需要对语言模型进行规范、改正,让它可以依照我们期望它输出的模样进行输出。具体的方式就是将一大堆人工标注好的范例输入到语言模型当中,这里所说的“人工标注好的范例”是指人为处理过的一些数据,包括答题要求和标准答案等。通过这些范例的大量输入告知 ChatGPT 应当如何回答。
经过以上三个方面的训练以后,ChatGPT 就已可以很规范的回答我们的问题了。固然至此想让它具有中立、客观、安全的语言描写能力或者不够的,还需要对 ChatGPT 进行最后的创意引导,具体的做法就是让任何用户对它进行自由发问,然后 ChatGPT 无干预的自由回答,最后人工告知它哪一个回答的好,哪一个回答的不好,并分别给予嘉奖/惩罚。这些做法是在规范 ChatGPT 的表现,使它尽量的作出符合人类认可的回答。
综上,ChatGPT 大语言模型的训练进程为:预训练→模板规范→创意引导。正是这三个步骤,再基于超大范围的数据造就了今天的最强语言模型 ChatGPT。
◈在 ChatGPT 大模型时期,我们应当怎样做?
可能会胡编乱造;
可能会混淆,把一个人身上的事情用到另外一个人身上;
没法直接操作,我们没有办法像操作数据库一样去操作它;
还存在一定的安全隐患,如某些机密性的信息;
更新效力低;
没法把语言和现实进行映照。
即便再强,也还有很大的优化空间。事实上目前还有很多人对 ChatGPT 存在着抵牾心理,由于在他们的认知中,ChatGPT 会造成大量的人员失业乃至是替换人类。但我想说的是“ChatGPT 其实不会让你失业,熟练使用 ChatGPT 的人材会让你失业”。我们应当做的是拥抱科技、拥抱 ChatGPT,接受它并优化自己的学习方法,毕生学习。
只有我们本身加入到科技发展的进程中,才不会被科技发展所淘汰。
桂(哥(网(络www.gUIgEge.cn
TikTok千粉账号购买:https://www.tiktokfensi.com/
本文来源于chatgptplus账号购买平台,转载请注明出处:https://chatgpt.guigege.cn/jiaocheng/29211.html 咨询请加VX:muhuanidc
