Nature正刊:谷歌推出医学版ChatGPT,未来的医生会被取代吗?
本文编辑:科研小通
chatgpt中文版 http://chatgpt.guige.xyz
ChatGPT大数据模型就应当用在有用的领域,比如医疗!那末医生会被取代吗?
学医造福人民,但是城里医院跟县里的医院医疗水平差距就很大,城里的医生比县里的医生的医术也要高很多,想要真正做到全民共享医疗资源谈何容易。
但是看了谷歌的数据大模型,未来或许可以精准化就诊,甚么病,甚么症状都能对阵下药,对普通病患可以提供最好最对的医疗资源!
学医造福人民,但是城里医院跟县里的医院医疗水平差距就很大,城里的医生比县里的医生的医术也要高很多,想要真正做到全民共享医疗资源谈何容易。
但是看了谷歌的数据大模型,未来或许可以精准化就诊,甚么病,甚么症状都能对阵下药,对普通病患可以提供最好最对的医疗资源!
医学ChatGPT
是福是货
近日,谷歌和谷歌旗下人工智能公司DeepMind的研究团队在Nature期刊上发表了一篇名为Large language models encode clinical knowledge的论文,研究大型语言模型(Large language models,LLMs)编码临床知识。能够在Nature期刊上发文,含金量不用再多做强调了。

文献网址:https://www.nature.com/articles/s41586-023-06291⑵/
大型语言模型(LLM)已展现了使人印象深入的能力,但临床利用的门坎很高。评估模型临床知识的尝试通常依赖于基于有限基准的自动评估。

为了解决这些局限性,研究团队提出 MultiMedQA,一个结合现有的六个医疗问题回答数据集,逾越专业医学,研究和消费者查询和一个新的医疗问题数据集在线搜索,HealthSearchQA的基准,包括3173个常见搜索的消费者医疗问题的数据集。
通过这一基准来评估大语言模型回答医学问题的真实性、在推理中使用专业知识、有用性、准确性、健康公平性和潜伏危害。
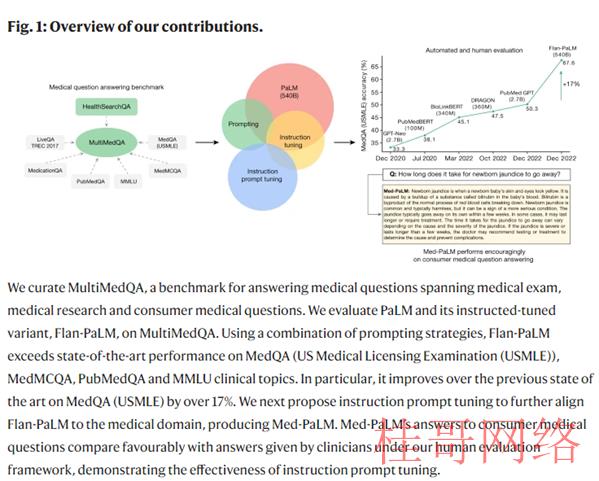
结果发现,使用 Flan-PaLM 和提示策略的组合,在 MedQA,MedMCQA,PubMedQA 和 MMLU 临床主题数据集上展现了先进的性能,超过了几个强大的 LLM 基线。
来看一些数据:在 MedQA 上到达了67.6% 的准确率(比之前的最新水平高出17% 以上) ,在 MedMCQA 上到达57.6% ,在 PubMedQA 上到达79.0%。但是进一步评估显示,它在回答消费者的医疗问题方面或者存在差距。
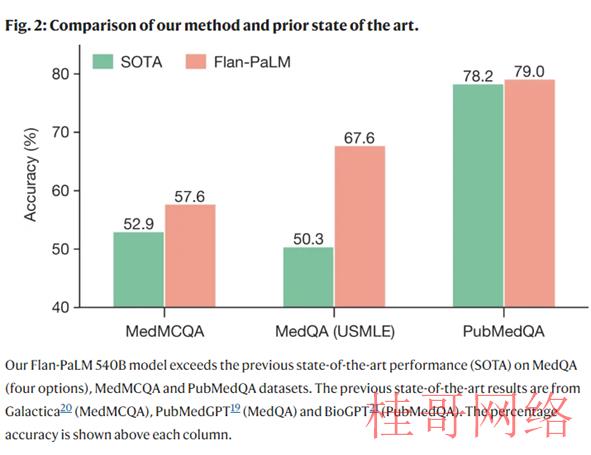
为了能够解决上述的问题,研究团队使用一种设计指令微调(instruction prompt tuning)的方式,进一步调试Flan-PaLM适应医学领域。
结果产生的新模型Med-PaLM在试行评估中表现相当不错,再来看一组数据:我们认为临床医生的回答在92.9%的问题中与科学共鸣一致,而Flan-PalM仅在61.9%的答案中与科学共鸣一致,对其他问题,答案要末与共鸣相反,要末不存在共鸣。
这表明,通用教学调剂本身不足以产生科学和临床基础的答案。但是,92.6% 的 Med-PalM 答案被认为符合科学共鸣,显示了教学及时调剂作为一种调剂技术的气力,以产生科学根据的答案。
一样地,Flan-PaLM有29.7%的回答被评为可能致使有害结果,Med-PaLM仅5.9%,相当于临床医生的回答的6.5%。
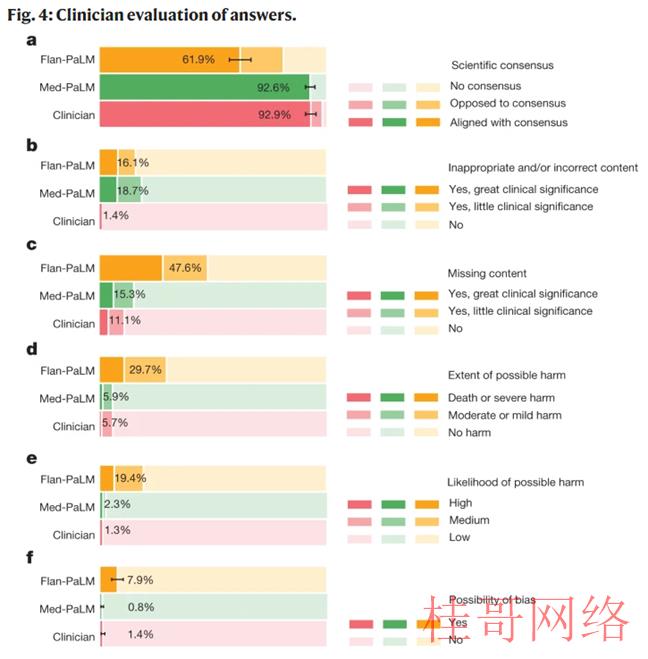
整体来看,Med-PaLM是一个强大的专精医学领域的大语言模型,而设计指令微调是一种有效的数据和参数校准技术,能够提高大语言模型的准确性、真实性、一致性、安全性,减少危害和偏差等因素,有助于缩小模型与临床专家的差距,使这些模型更接近现实世界的临床利用。
医学ChatGPT
是福是货
近日,谷歌和谷歌旗下人工智能公司DeepMind的研究团队在Nature期刊上发表了一篇名为Large language models encode clinical knowledge的论文,研究大型语言模型(Large language models,LLMs)编码临床知识。能够在Nature期刊上发文,含金量不用再多做强调了。
文献网址:https://www.nature.com/articles/s41586-023-06291⑵/
大型语言模型(LLM)已展现了使人印象深入的能力,但临床利用的门坎很高。评估模型临床知识的尝试通常依赖于基于有限基准的自动评估。
为了解决这些局限性,研究团队提出 MultiMedQA,一个结合现有的六个医疗问题回答数据集,逾越专业医学,研究和消费者查询和一个新的医疗问题数据集在线搜索,HealthSearchQA的基准,包括3173个常见搜索的消费者医疗问题的数据集。
通过这一基准来评估大语言模型回答医学问题的真实性、在推理中使用专业知识、有用性、准确性、健康公平性和潜伏危害。
结果发现,使用 Flan-PaLM 和提示策略的组合,在 MedQA,MedMCQA,PubMedQA 和 MMLU 临床主题数据集上展现了先进的性能,超过了几个强大的 LLM 基线。
来看一些数据:在 MedQA 上到达了67.6% 的准确率(比之前的最新水平高出17% 以上) ,在 MedMCQA 上到达57.6% ,在 PubMedQA 上到达79.0%。但是进一步评估显示,它在回答消费者的医疗问题方面或者存在差距。
为了能够解决上述的问题,研究团队使用一种设计指令微调(instruction prompt tuning)的方式,进一步调试Flan-PaLM适应医学领域。
结果产生的新模型Med-PaLM在试行评估中表现相当不错,再来看一组数据:我们认为临床医生的回答在92.9%的问题中与科学共鸣一致,而Flan-PalM仅在61.9%的答案中与科学共鸣一致,对其他问题,答案要末与共鸣相反,要末不存在共鸣。
这表明,通用教学调剂本身不足以产生科学和临床基础的答案。但是,92.6% 的 Med-PalM 答案被认为符合科学共鸣,显示了教学及时调剂作为一种调剂技术的气力,以产生科学根据的答案。
一样地,Flan-PaLM有29.7%的回答被评为可能致使有害结果,Med-PaLM仅5.9%,相当于临床医生的回答的6.5%。
整体来看,Med-PaLM是一个强大的专精医学领域的大语言模型,而设计指令微调是一种有效的数据和参数校准技术,能够提高大语言模型的准确性、真实性、一致性、安全性,减少危害和偏差等因素,有助于缩小模型与临床专家的差距,使这些模型更接近现实世界的临床利用。
桂@哥@网@络www.guIgegE.cn
TikTok千粉账号购买:https://www.tiktokfensi.com/
本文来源于chatgptplus账号购买平台,转载请注明出处:https://chatgpt.guigege.cn/jiaocheng/37428.html 咨询请加VX:muhuanidc
