ChatGPT类利用服务,数据合规的看法

作者:王融腾讯研究院首席数据法律专家
chatgpt中文版 http://chatgpt.guige.xyz
上一篇链接:《大模型研发者是数据控制者么?》
本期观点摘要:
1. ChatGPT等AI利用公司直接面向个人提供服务,搜集并处理个人信息,可被视为个人信息保护合规主体——数据控制者。
2.与移动互联网APP的典型场景相比,生成式AI公司的个人信息处理活动有其本身特点,数据合规重点也有所区别。
3.根据GDPR,欧盟数据保护机构(DPA)是监管机构,而非市场准入机构,其职责主要在指点催促企业满足数据合规要求。
4.未来真实的挑战来自于AI赋能的各类利用服务,解决新的数据安全问题需要新思惟。
C端AI利用公司是
数据控制者(data controller)
并不是所有的市场主体都是数据合规框架下的义务主体,需要根据技术原理、业务场景和法律规范来进一步肯定。当主体身份重合时,也需基于区别业务流程匹配合规义务。基于此分析框架,我们在上一篇文章里详细论证了大模型研发者,在模型研发阶段有可能其实不认定为隐私数据合规上的法律主体(data controller)。
基于一样的分析框架,我们认为面向C端个人用户提供生成式AI服务的运营者可被认定为隐私数据合规上的数据控制者。例如,当OpenAI在2022年11年面向公众发布ChatGPT利用服务,并在2个月内突破1亿用户,成为历史上增长最快的消费者利用时,作为数据控制者的身份已肯定无疑。
事实也如此。从海外实践看,目前已面向个人的AI利用公司,在数据合规部份已完全配置隐私政策和用户协议,以充分告知用户搜集了哪些类型的数据,和怎么处理数据。OpenAI在隐私政策中罗列了搜集类型[1];包括账户信息、通讯内容、使用记录等;数据处理的目的包括但不限于:提供、改进服务,预防讹诈,网络信息安全、实行法定义务所需等。类似的,面向公众的图片生成AI公司Midjourney 也提供了清晰明了的隐私政策[2]。国内目前虽然没有正式上线的产品,但已有部份厂商在测试版本中嵌入隐私政策。

这也就不难解释为何数据保护机构DPA是第一批入场的监管机构。3月31日,意大利数据监管机构Garante宣布暂时制止ChatGPT,并要求OpenAI 在20天内相关问题作出回应[3]。这是数据监管机构DPA对一项新兴利用的正常反应,但被误读为DPA可以对特定业务采取永久性措施。相反,根据欧盟GDPR,DPA虽然有天价处罚权,但其职权被严格限制在改正性权利范围内,包括建议,正告和暂时性的或具有明确期限的禁令[4]。换言之,只要服务提供者满足数据合规要求,则DPA不得对其采取市场禁入措施。在其临时制止令遭到广泛批评后,4月12日,Garante释放信号:“如果 OpenAI 采取有效措施,我们准备在 4 月 30 日重新开放 ChatGPT”[5]。
生成式AI公司
数据合规的独特性
与移动互联网相比,面向个人的生成式AI利用在数据合规上有很多类似的地方,包括制定隐私政策、业务协议,明确处理用户数据的合法性基础,通过隐私保护设计在信息系统中支持用户围绕其账户信息和使用服务进程中产生的个人信息的相关权利,包括查询、访问、更正、删除等。但一方面,我们更加关注其在个人信息处理活动中的独特性:
第一、搜集的个人信息种类相对较少。导航软件、打车、购物等典型的移动APP为实现对用户个性化服务的闭环,需要实时搜集用户较多类型的个人信息;而目前的生成式AI利用,以OpenAI和Midjourney为例,从其底层逻辑动身,其更加关注生成内容的质量,在利用服务阶段搜集个人信息主要是建立用户账户体系,接受用户指令(prompt)并与之交互,因此搜集的个人信息相对较少,包括账户信息(用户名、邮件)、使用记录(cookie等),如果触及租赁服务等交易,则还包括支付信息。因此,Midjourney更是以表格的情势,明确列出了不搜集的用户信息种类:包括用户敏感信息,生物辨认信息、地理位置信息等等。这些信息对生成式AI利用确切也无关紧要。
第二、在更早阶段和更广泛地采取个人信息去标识化和匿名化措施。在提供服务进程中,生成式AI主要围绕用户账号体系及通讯内容构建数据安全防护体系。以ChatGPT为例,虽然在模型训练阶段,其收集的数据源中的用户个人信息较少(且主要为公然信息),但在利用服务阶段,问答式的会话功能会产生较为敏感的通讯内容,模型根据与用户通讯内容(上下文环境)进一步分析并生成回复。为下降用户通讯内容泄漏后产生的风险,生成式AI会在更早阶段采取用户身份信息去标识化及匿名技术,或将用户身份信息与通讯内容相互分离,或在模型生成回复内容后及时删除通讯内容等安全类措施。这也是由生成式AI更关注反馈内容,而非用户行动的逻辑所决定,这与建立在用户行动特点基础上,以个性化推荐见长的移动APP有显著差异。
第三、由以上两方面影响,生成式AI与移动APP在数据安全的风险领域有所区别。移动互联网APP需要直接搜集大量个人信息,用户数据库易成为黑客攻击和数据泄漏的目标。但是,在生成式AI 利用中,虽然其直接搜集的用户信息种类少,但其风险集中在模型被攻击从而反向溯源数据库,和用户通讯内容泄漏的隐患。意大利数据监管机构对OpenAI发出暂时禁令,即是由于用户通讯内容因出现服务bug而泄漏的事故。为减微风险,在技术上已明显具有先发优势的OpenAI,开始探索支持用户可以选择将个人删除通讯记录。4月23日,OpenAI 推出新控件,允许 ChatGPT 用户可以选择关闭其聊天历史记录,且可以不用于模型训练目的[6]。

第四、在输出阶段,如果用户引导的问题触及个人信息时,基于大模型的语言预测生成的算法逻辑,输出结果中的个人信息有多是编造的,虚假的,这可能违背了个人信息保护法上的信息质量原则,即保持个人信息准确性要求。但这类问题的背后实质是生成式AI在内容治理中面临的一般性问题,即AI进入“空想”,编造不准确乃至是虚假的信息。
OpenAI在研发阶段,即致力于改良和解决此类问题,包括引入人类专家意见反馈机制和强化学习(RLHF),引导AI输出准确内容。目前,部份生成类AI还加入了输入(prompt)+输出两重过滤机制,来进一步避免出现有害内容或侵权问题。虽然大语言模型的进步速度使人瞠目结舌,仅用了4个月,ChatGPT 4相比于GPT3.5,其输出信息的准确率就大幅提升了40%,违背内容政策的输出可能性下降 82%[7],但目前仍不能保证其生成内容具有可靠的准确性。因此作为用户也应当对ChatGPT的回答保持一定警惕和判断力,避免被误导。
综上,看待生成式AI的数据合规问题,需要从移动互联网服务中的数据合规惯性中跳脱出来,围绕其在隐私和数据安全方面的区别特点,有的放矢采取相应的合规和安全保护措施。
面向未来的挑战:
史无前例的数据会聚
基于大语言模型的生成式AI为众人所注视,不在内容生成,而在其所具有的通用人工智能(Artificiall general interlligence,AGI)潜力,业界惊呼:AGI的奇点时刻正在到来。未来,除面向普通大众的内容生成式AI利用外,业界普遍认为AI也将改写互联网范式。现有商业模式将广泛引入AI智能模型,大幅提升用户交互效力。这不是将来时,而是进行时。2023年3月17日,微软发布Microsoft 365 Copilot,将大语言模型(LLM)功能与微软办公利用相结合,帮助用户解锁生产力[8]。
Copilot将会被内置到办公全家桶内,在Word、Excel、PowerPoint中,AI将与个人通过便捷的语言交互,一起撰写文档,演示文稿,实现数据可视化;在Outlook,Teams ,Business Chat中,AI能够帮助用户回复邮件,管理邮箱,实时完成会议摘要和待办事项,提高会议效力。
这只是未来超级数字助理的雏形,在智能基础设施的支持之下,每一个人乃至可以具有多个数字分身,协同完成任务。可以想见,数字助理的背后是大语言模型访问、链接个人和商业企业的私有数据,数据的融会利用一定是无缝丝滑的。此类数据的访问处理怎么以安全、合规、保护隐私的方式进行,对安全技术保障措施提出了更高要求。
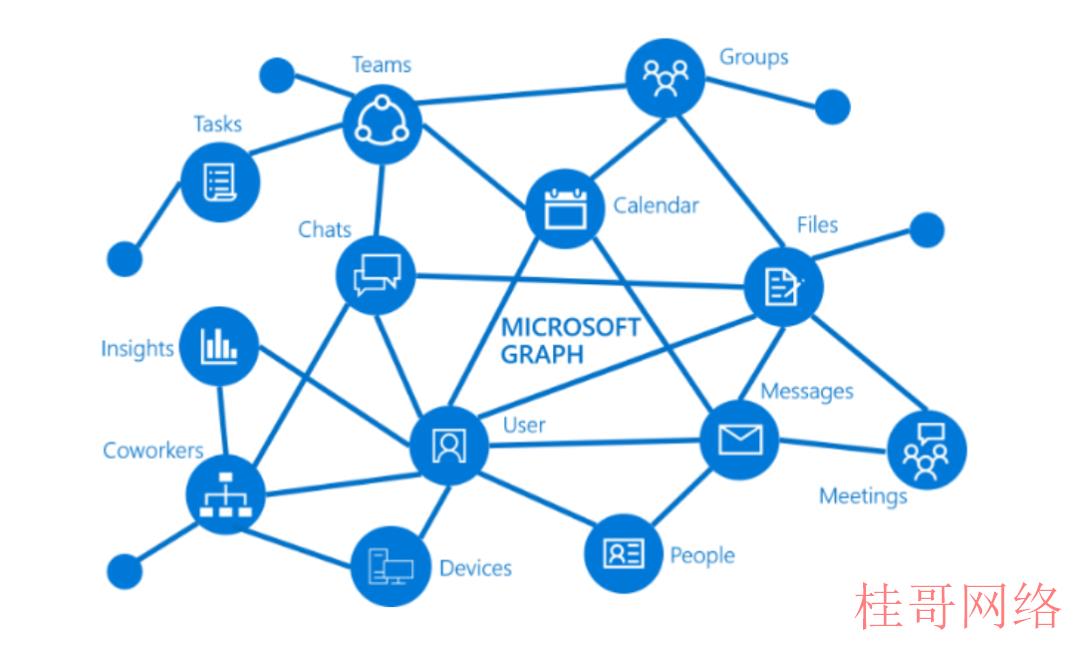
图:Microsoft Graph 是 Microsoft 365 中数据和智能的网关。它提供了统一的可编程性模型,以安全便捷地跨业务平台访问数据。
同时,我们也迫切需要审视现有的隐私保护与合规机制。在当前移动互联网个人信息保护实践中,对必要性原则解释是非常严苛的,以最大程度的避免数据搜集与会聚。例如:《常见类型移动互联网利用程序必要个人信息范围规定》(简称《39类规定》)不但针对每类利用辨别了基本功能和附加功能,还针对基本功能搜集的必要信息进行了明确。在大部份基本功能中仅能搜集两三类个人信息,例如定位和导航功能仅能搜集位置信息、动身地、到达地三种信息;《App背法背规搜集使用个人信息行动认定方法》中更是明确:不得仅以改良服务质量、研发新产品等理由搜集个人信息。这类基于“严防死守”的数据合规思路在未来的AI利用场景中会不会还可以继续走下去,是一个值得探讨的问题。
从移动互联网到我们正在步入的AI时期,虽然数据利用一直在向更广更深的方向发展,但各类新技术利用仍将隐私保护作为价值对齐(value alignment)的重要方面。隐私和数据安全的真理历来也不是对数据的使用进行各种限制,或人为增加数据利用门坎,而在于通过剧烈的市场竞争、健全的法律机制和更加强大的技术安全措施来切实保障用户隐私与数据安全。
[1]https://openai.com/policies/privacy-policy
[2]https://docs.midjourney.com/docs/privacy-policy
[3]https://www.gpdp.it/web/guest/home/docweb/-/docweb-display/docweb/9870832
[4]GDPR Article 58&Article 83
[5]https://www.reuters.com/technology/italys-data-watchdog-ChatGPT-can-resume-april⑶0-if-openai-takes-useful-steps⑵023-04⑴8/
[6]https://openai.com/blog/new-ways-to-manage-your-data-in-chatgpt
[7]https://openai.com/product/gpt⑷
[8]https://news.microsoft.com/zh-cn/microsoft⑶65-copilot/
[9]https://privacy.microsoft.com/zh-cn/privacystatement
桂,哥,网,络www.GuIgege.cn
TikTok千粉账号购买:https://www.tiktokfensi.com/
本文来源于chatgptplus账号购买平台,转载请注明出处:https://chatgpt.guigege.cn/jiaocheng/29889.html 咨询请加VX:muhuanidc
