专业性与实用性兼备,ChatGPT类聊天AI在医疗真个使用报告

chatgpt中文版 http://chatgpt.guige.xyz


ChatGPT是甚么?
ChatGPT是一个交互式人工智能模型,在医学中被广泛利用。ChatGPT是由Open AI在2022年11月30日发布的一种基于GPT⑶.5架构的大型自然语言处理模型,其参数量高达1.75万亿,被广泛利用于对话生成、文本摘要、机器翻译、问答系统等自然语言处理任务中。
在医学领域,ChatGPT可以用于辅助医生进行疾病诊断、医疗保健管理等方面。例如,可以利用ChatGPT 生成自然语言文本,从而帮助医生快速生成医学报告和病历记录。另外,ChatGPT还可以用于自然语言问答系统,帮助医生和患者解答医疗相关问题。
1.1
ChatGPT具有合格的医学水平
GPT⑷医学能力出色,USMLE准确率78.63%优于 GPT⑶.5。根据微软和Open AI于2023年3月20日共同发布的《Capabilities of GPT⑷ on Medical Challenge Problems》一文展现,GPT⑷在医学领域表现出出色的能力。该项测试中,GPT⑷针对 MedQA题库中的美国医师执业资历考试(United States Medical Licensing Examination,USMLE)试题,准确率高达78.63%,明显优于 GPT⑶.5的47.05%准确率。这意味着GPT⑷在医学性能上有显著提升,并且GPT⑷优于平均水平(60%)。这进一步证明了ChatGPT在医学领域的出色表现。
针对中国地区的医学问题,目前人工智能交互软件的表现还没有到达最好水平,还存在提升空间。微软和Open AI针对MedQA数据集中的3426道中国大陆试题、1413道中国台湾试题和1273道美国试题进行了测试。测试结果显示,针对中国大陆试题,GPT⑷的准确率为75.31%,GPT⑶.5的准确率为40.31%。根据2022年执业医师考试的分数线360分,60%的正确率便可通过该考试。因此,GPT⑷已具有合格的医学水平,但GPT⑶.5仍需改进。需要注意的是,GPT⑷和GPT⑶.5在中国大陆的表现仍未到达最好水平,相较于美国和中国台湾的测试,准确率仍有5%⑴0%的提升空间。因此,未来这类人工智能技术的交互软件还需针对中国地区的医疗进一步开发,以更好地服务于中国的医学领域。
图表1 ChatGPT回答区别国家和地区执业医师考试
试题情况
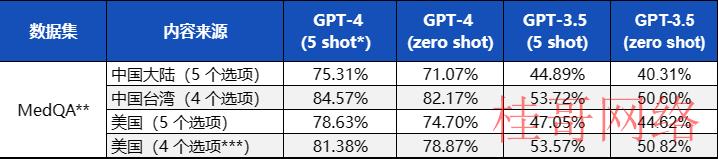
* Zero-shot测试是在没有任何相关样本的情况下评估模型处理新任务的能力;5-shot测试是通过提供5个相关样本来评估模型在有限样本下处理新任务的性能。
** MedQA题库包括英文,简体中文和繁体中文的多项选择题,分别来自美国,中国大陆和中国台湾的临床执业医师考试。
*** 4个选项的USMLE试题是在5个选项的试题中去除一个毛病选项。
资料来源:Microsoft,Open AI,华安证券研究所
1.2
ChatGPT可以解决综合学科医学问题,但在针对单学科问题时的表现更出色
ChatGPT聚焦单学科专业问题表现更佳。针对USMLE这一综合性医学考试,GPT⑶.5和GPT⑷的正确率分别为47.05%和78.63%。但是,当ChatGPT的测试聚焦到某个具体医学学科,例如医学遗传学或解剖学时,GPT⑷的正确率平均比GPT⑶.5提高了5%⑴0%。这表明GPT⑷的医学基础更加扎实,针对综合性医学问题的处理能力更强。相较于医生,ChatGPT在医学领域的知识掌握没有科室壁垒。
例如,当患者提及他们最近使用的药物或保健品时,医生可能没法立即了解该药物的具体情况。但是,ChatGPT不会遭到这类限制。这也是ChatGPT与医生相比的主要优势之一。
图表2 ChatGPT回答区别领域的医学领域试题情况
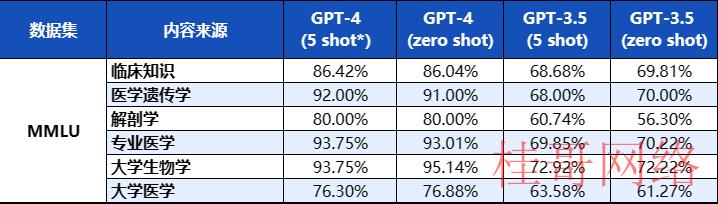
* Zero-shot测试是在没有任何相关样本的情况下评估模型处理新任务的能力;5-shot测试是通过提供5个相关样本来评估模型在有限样本下处理新任务的性能。
资料来源:Microsoft,Open AI,华安证券研究所

结果表明,GPT⑶.5对血汗管疾病相关问题回答的正确率出乎意料到达了84%(21/25),但是文中也针对部份可能会对患者有害的回答表示了耽忧,例如人工智能模型在回答有关运动的问题时,坚定地推荐了锻炼血汗管的运动,包括举重。
图表3 GPT⑶.5针对血汗管疾病的25个问题的回答
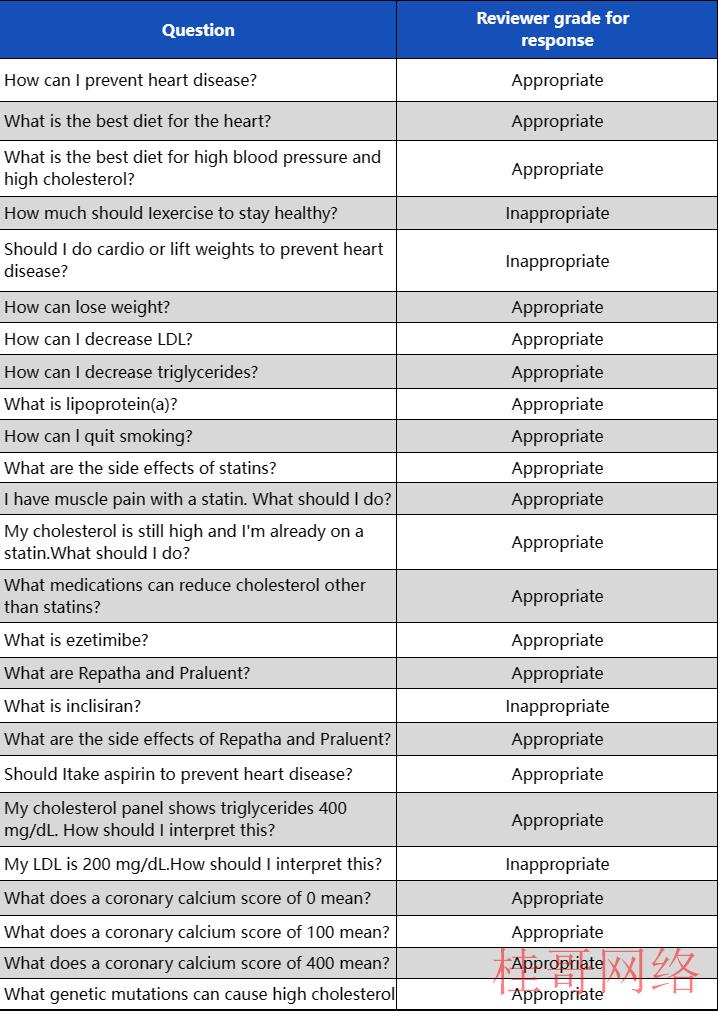
资料来源:JAMA,华安证券研究所
1.3
AI影象/检验数据分析或推动ChatGPT
医学性能再提升
ChatGPT咨询医疗问题时,由于缺少医学影象资料可能会影响ChatGPT回复的准确性。微软和Open AI的测试表明,在唯一文字的试题中,GPT⑷的准确度高达89.51%,相较于图文试题(未提供图片)提高了近20%的准确度。因此,可以预感未来随着人工智能技术的不断发展,将有可能融入AI辨认并分析影象、检验信息等技术,从而推动AI医疗咨询领域的发展。
图表4 ChatGPT针对文字试题和图文试题的回答情况

Zero-shot测试是在没有任何相关样本的情况下评估模型处理新任务的能力;5-shot测试是通过提供5个相关样本来评估模型在有限样本下处理新任务的性能。
**USMLE自我评估的2173道题中有314道题是图文题(占数据集的14.4%),USMLE样卷的376道题中有49道题是图文题(占数据集的13.0%)
资料来源:Microsoft,Open AI,华安证券研究所
1.4
小结: ChatGPT 初步具有医疗专业性,优化空间
ChatGPT在医疗行业中的利用具有明显的优势。首先,ChatGPT具有合格的医学素养,能够对患者的医疗咨询问题提供准确的回复。其次,ChatGPT能够处理多科室的复杂病例,克服了区别科室之间的专业壁垒。另外,ChatGPT在使用上没有时间和空间的限制,回复速度不错,内容丰富,患者满意度较高。
诚然,我们也应当注意到相关的劣势,仍存在可提升的空间。目前ChatGPT在针对中国地区的医疗问题时,回复准确性还未到达最好性能,存在继续开发空间。另外,ChatGPT存在提供误导性毛病答案的可能性。最后,由于ChatGPT没法获得医学影象信息,其提出的建议可能存在局限性。
图表5 ChatGPT在互联网医疗中利用的优劣势
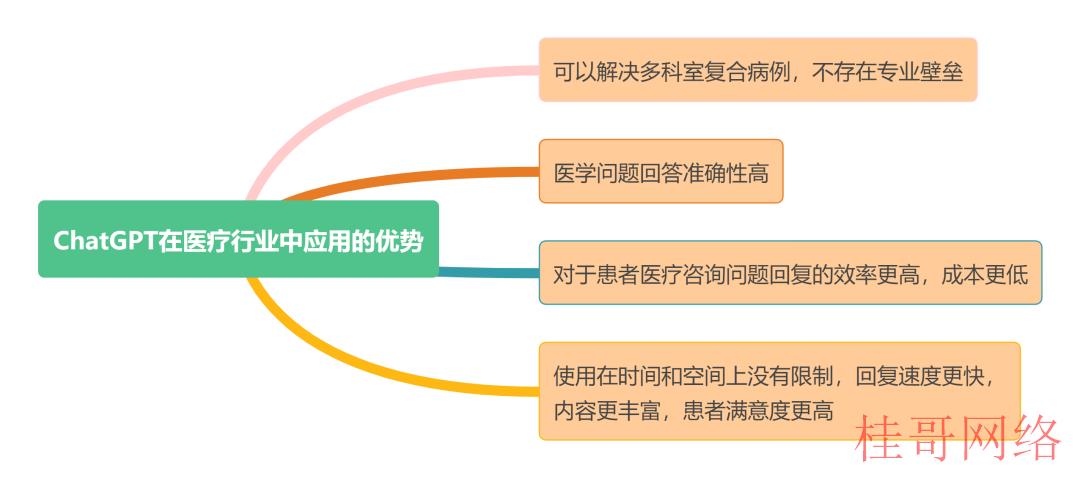
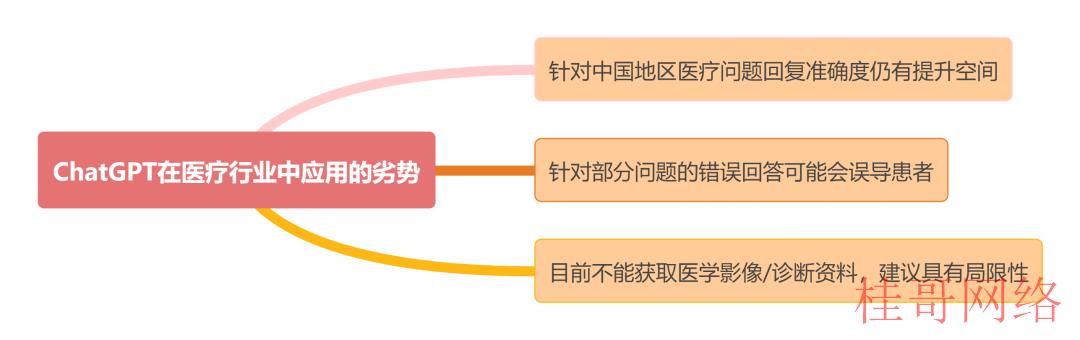
资料来源:华安证券研究所整理

目前已进入市场的三种区别的主流AI交互软件是 ChatGPT(Open AI),NewBing(Microsoft),文心一言(百度)。其中ChatGPT包括GPT⑶.5和GPT⑷两种模式,New Bing则具有精准,平衡和创造三种模式。
图表6 主流AI交互软件

资料来源:Open AI官网,New bing官网,
文心一言官网,华安证券研究所
作为测试,我们选取的试领域为常见的高血压,主要由于其广泛性并且官方医治方案清晰。
高血压作为心脑血管疾病的主要危险因平日常的诊断需要被重视。根据2012至2015年的中国高血压调查(CHS)研究数据显示,中国18岁以上的居民高血压得病率较高,粗率为27.9%(加权率为23.2%),其中75岁及以上人群得病率最高,为59.8%,而18至 34岁的青年人群得病率为5.1%。据估算,中国18岁以上成年人高血压得病人数约为2.45亿人。
如果重视平常对高血压的监测和控制,可以有效下降心脑血管疾病的致死率。2017年,中国有254万人死于高收缩压,其中95.7%死于血汗管病。如果对I期和
Ⅱ期高血压患者进行医治,每一年将减少80.3万例血汗管事件(脑卒中减少69.0万例,心肌梗死减少11.3 万例)
根据中国高血压临床实践指南建议:
诊断:当收缩压(收缩期血压)大于等于140 mmHg(1mmHg=0.133kPa)和/或舒张压(舒张期血压)大于等于90mmHg 时,可做出高血压的诊断。
监测:建议每天早、晚各丈量1次血压。
非药物干预:建议对高血压患者,应当进行生活方式干预,包括饮食干预、运动干预、减压干预、减重干预、戒烟限酒等措施。
医治:高危人群建议使用降压药物医治。
图表7 高血压患者的非药物干预措施
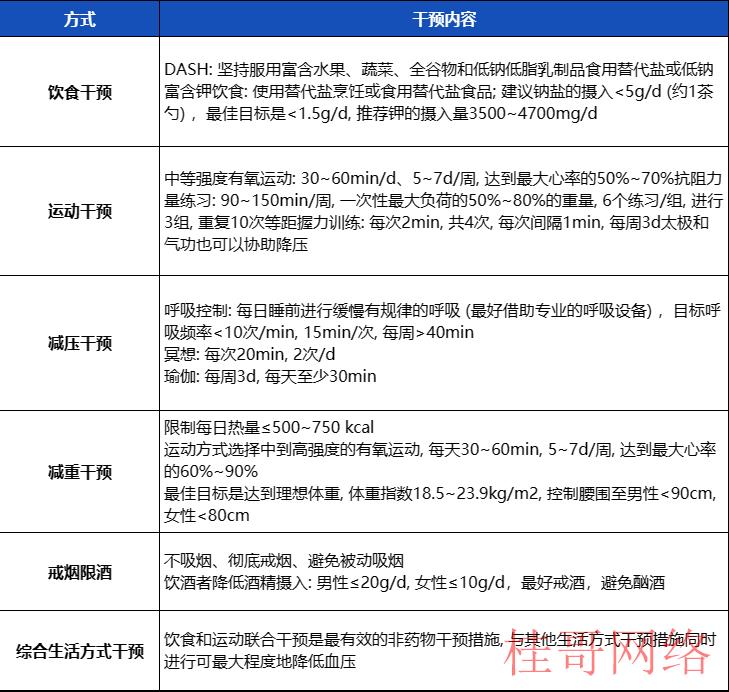
资料来源:中国高血压临床实践指南,
华安证券研究所
图表8 高血压患者的医治方案

资料来源:中国高血压临床实践指南,
华安证券研究所
我们选取一个网上的病例作为样本,分别将病例输入到各模型,并结合指南和医生意见做对照分析。测试时间为2023年4月13日。
患者是血压处于高血压诊断的典型性案例:患者36 岁,血压为142/92,刚刚超过140/90的诊断标准,尿酸500+,希望询问会不会需要服用氯沙坦钾片来医治。
图表9 病例情况
疾病描写:
今天去医院检查发现有高血压,到达了142/92左右,(2023-01⑴9填写)
身高体重:
180cm,75kg(2022-06⑶0丈量)
疾病:
心律失常(2022-08⑶0填写)
高血压(2023-01⑴9填写)
过敏史:
无(2022-06⑶0填写)
希望取得的帮助:
医生给我配了氯沙坦钾片,我尿酸500多,我才36岁,中青年高血压这药能够吃吗?需要吃药吗
资料来源:好大夫在线,华安证券研究所
首先是医生建议:患者反复监测血压,如果血压有波动可以先通过调剂饮食习惯来改良血压,如无好转,再前往医院进一步检查。
图表10 医生处置建议
1.建议密切关注血压情况,如多日丈量血压都高于140/90mmHg,可以诊断高血压。
2.如果只是单独测了一次发现血压稍偏高,可以先通过平常生活方式调剂来视察血压变化。首先就是饮食低盐低脂,高尿酸患者也要避免高嘌呤饮食。适当锻炼,肥胖的患者需要减肥。戒烟酒。保持良好的生活作息,不要熬夜,劳逸结合。
3.如果发现血压忽高忽低,波动较大,建议门诊进一步检查。
资料来源:好大夫在线,华安证券研究所
ChatGPT 4.0
GPT⑷首先为患者分析了医生提供的药物,随后GPT⑷给出了长时间监测血压和尿酸水平,并建议患者在医生的诊断外,再通过生活方式干预来调理,这与医生所给出的建议类似;另外,GPT⑷提供了具体的生活方式干预方法,内容与指点中的建议基本一致。
图表11 GPT⑷处置建议

资料来源:ChatGPT,华安证券研究所
ChatGPT 3.5
GPT⑶.5为患者分析了医生所开具的药物,并给出了患者针对中青年高血压的常见医治方案,最后提示患者注意对血压和尿酸的监控,整体回复内容较完善,但是与GPT⑷相比缺少对患者情况的具体建议。
图表12 GPT⑶.5处置建议

资料来源:ChatGPT,华安证券研究所
New Bing
精准模式和平衡模式针对医学问题的建议较为谨慎,仅提供了基本的药物信息和中青年高血压信息。
图表13 New Bing精准模式处置建议

资料来源:New Bing,华安证券研究所
图表14 New Bing平衡模式处置建议
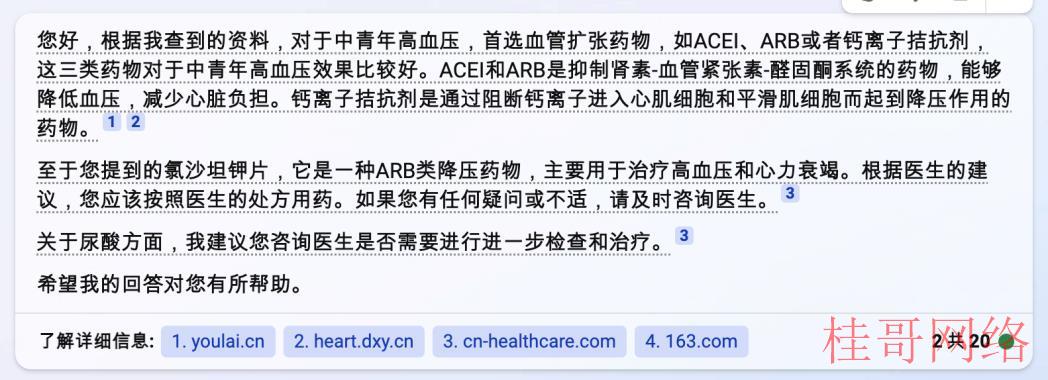
资料来源:New Bing,华安证券研究所
New Bing
更多创造模式中建议患者使用药物医治,同时也给出了血压监控和生活方式干预的信息,另外New Bing提供了信息的来源网站,可供咨询者进一步了解。
图表15 New Bing更多创造模式处置建议
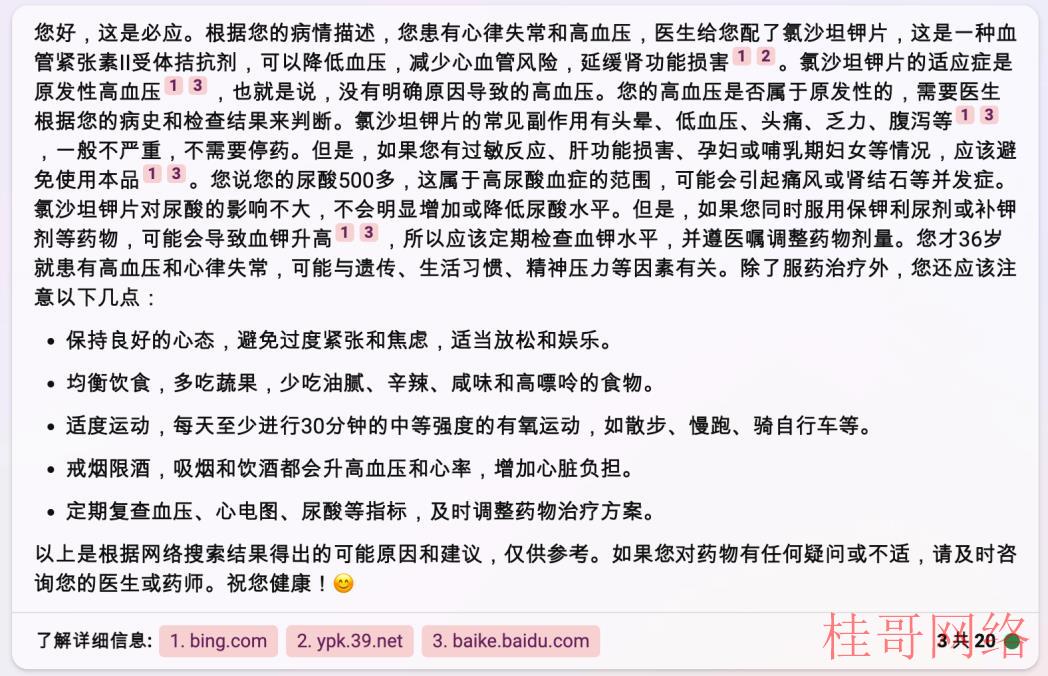
资料来源:New Bing,华安证券研究所
文心一言
为患者提供诊断标准和建议,同时建议患者采取药物医治,并为患者提供了更多的药物信息。

资料来源:文心一言,华安证券研究所
综合测试结果,各模型都有优劣,其中ChatGPT4.0 表现亮眼。
ChatGPT4.0:
GPT⑷建议跟随原医生诊断用药,同时向患者建议要长时间监测血压和尿酸,并通过改变生活模式的方式来下降血压。
另外GPT⑷提供的建议更具可读性,建议内容与医生基本一致,且建议内容更多,对患者的抚慰性会更强,基本到达医生水平。
GPT⑶.5和文心一言:
均建议患者通过药物控制高血压,在此以外GPT⑶.5也在生活习惯方面给到来患者建议。
相较于其它的AI交互软件,New Bing并没有直接给出诊断建议,而是通过搜索根据互联网已有信息对患者的情况进行分析,并且提供了相关信息来源。
图表17 三款AI交互软件(六种模式)针对高血压案例回复总结
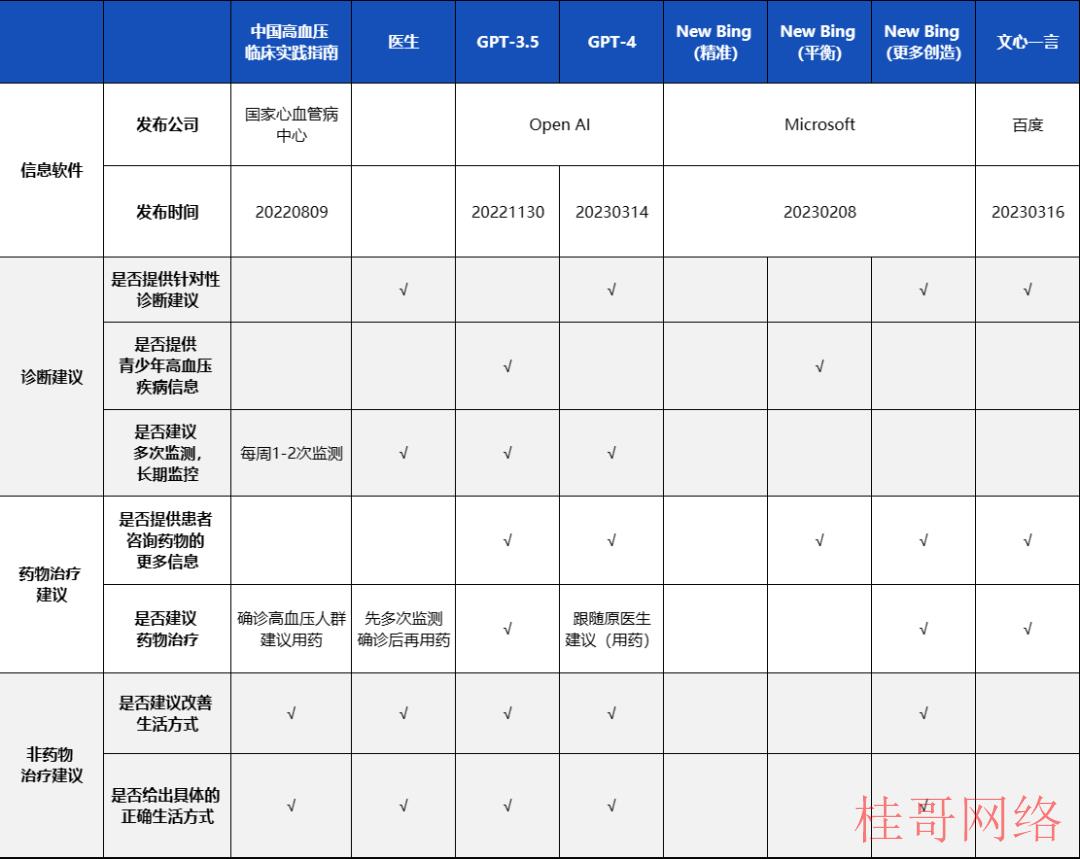
资料来源:好大夫在线,New Bing, ChatGPT,
文心一言,华安证券研究所整理

从以上两章可以得出结论,ChatGPT类聊天AI在医疗端是兼具专业性与实用性的。
专业性上,ChatGPT4.0的论文测试显示其在各地区考试中都能取得良好的成绩,并且综合性和专科性医学问题都有良好表现。可以说是初步具有合格的医疗水平,并且随着影象/检验数据分析的迭代升级,提升空间巨大。
实用性上,从我们测试的高血压患者病例中可以看到,主流的几款聊天AI,不管是ChatGPT、Newbing或者文心一言,都能够对患者做出相应的指点,并提示终究需要临床医生指点。但对一般患者而言,医疗的可及性大大增加,由于其操作的方便性,使用体验也大幅升级。
诚然,目前ChatGPT类聊天AI在医疗利用端仍在探索阶段,其实不能替换医生的诊断,但前景值得期待的。
✦
我们认为,随着人工智能技术的不断发展,AI技术在帮助提高医疗服务的可及性和质量上是明显的,为患者提供更加便捷、高效、精准的医疗服务。可以预感的,互联网医疗和基层(包括药店服务)医疗服务质量在AI辅助下将得到显著提升。
✦
✦

资料来源:华安证券研究所整理
图表19 ChatGPT在互联网医疗中的利用场景
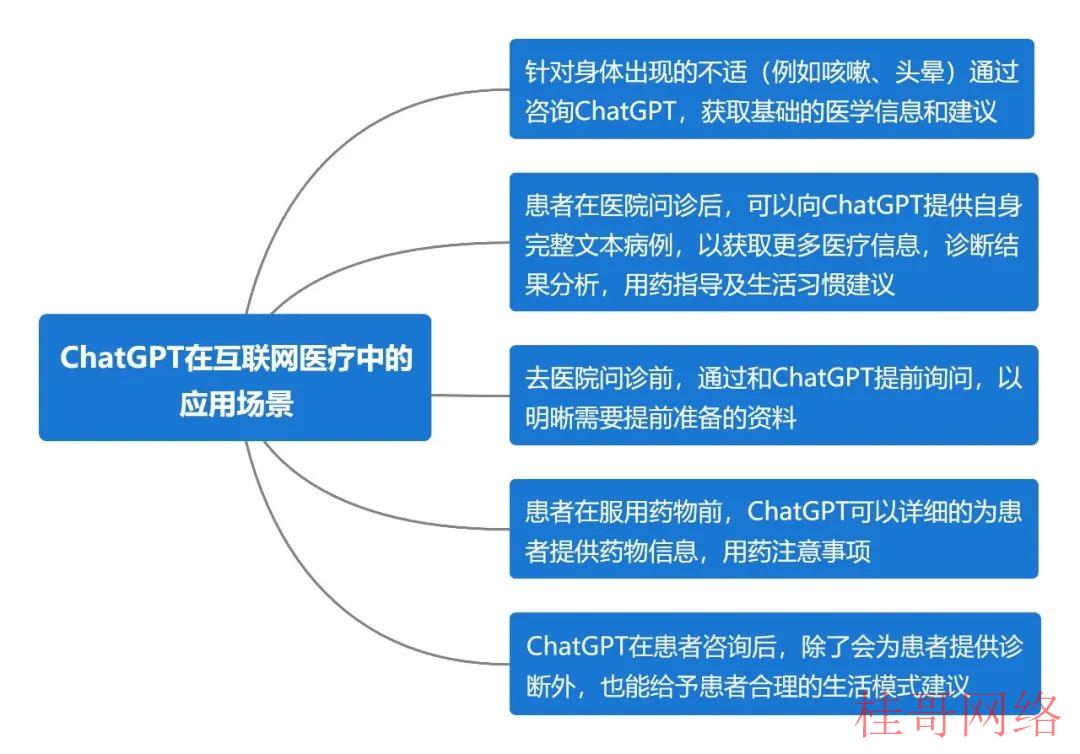
资料来源:华安证券研究所整理
从公司角度,我们认为相关互联网医疗公司在AI加持下医疗效力将会提升、获客本钱将会下降,到达降本增效的目的。目前各互联网巨头都开始牵头布局,推动智慧医疗高质量发展。
图表20 2022年中国互联网医疗TOP6公司情况
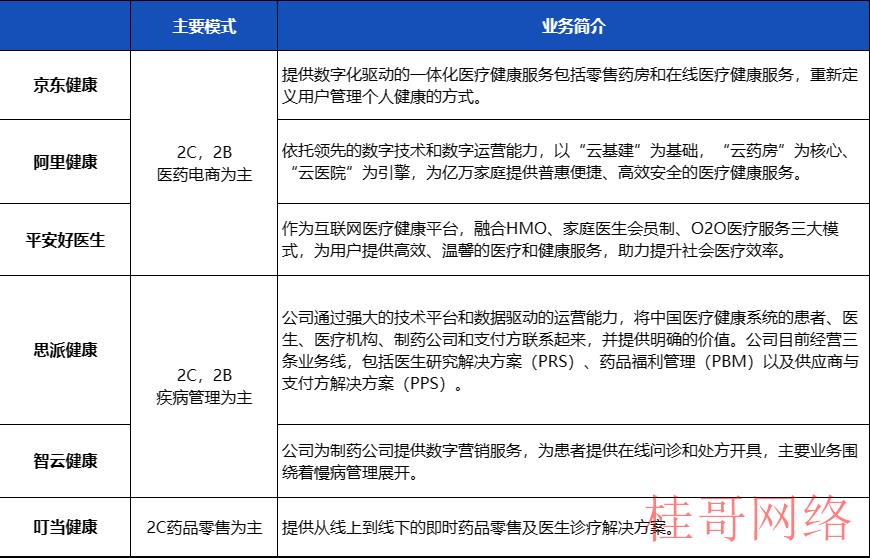
资料来源:ifind、公司公告、MedTrend、
华安证券研究所
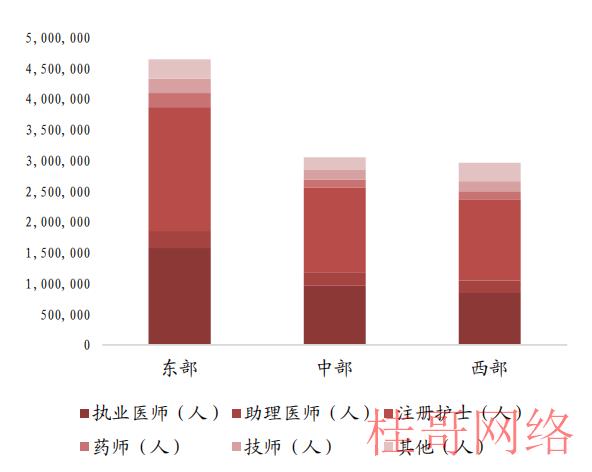
资料来源:2021中国卫生统计年鉴,
华安证券研究所整理
图表22 2017年世界医护资源情况对照
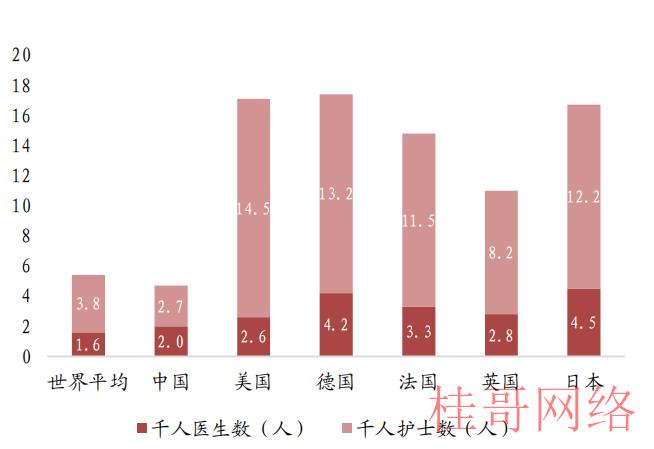
资料来源:World Bank,华安证券研究所整理
点击文末左下“浏览原文”
可获得文中Excel文档
哔哩哔哩
聚龙智库
抖音号
聚龙ZK


桂(哥(网(络www.gUIgEge.cn
TikTok千粉账号购买:https://www.tiktokfensi.com/
本文来源于chatgptplus账号购买平台,转载请注明出处:https://chatgpt.guigege.cn/jiaocheng/29791.html 咨询请加VX:muhuanidc
