ChatGPT原理科普
现在还有很多人找我问 GPT 的原理,给我发了一大堆不准确的博文,这里我也自己试着解释一下 ChatGPT 背后的原理,为何 ChatGPT 出现以后,旧的深度学习网络技术的优势渐渐意识
chatgpt中文版 http://chatgpt.guige.xyz
一、引言
1 .1 ChatGPT 简介
ChatGPT,全称 Chatbot based on Generative Pre-trained Transformers,是一种基于 GPT 架构的开放领域生成式对话机器人。通过构建在大量文本数据上预训练的语言模型,ChatGPT 能够理解自然语言并生成联贯、成心义的回复。与传统的基于规则或检索的对话系统相比,ChatGPT 更具灵活性和创造性,能够在多种利用场景中提供更加自然的人机交互体验。
ChatGPT的发展受益于深度学习、自然语言处理领域的最新技术,如Transformer结构、预训练与微调的策略等。借助这些技术,ChatGPT在语言理解、文本生成等多个任务上获得了显著的性能提升。同时,ChatGPT已在众多实际利用中展现出强大的潜力,如客户服务、语言教育、虚拟助手等。
但是,ChatGPT 仍面临一些挑战,如安全性与道德风险、模型运行效力、个性化与多样性等。未来的发展将致力于解决这些问题,为用户带来更加智能、高效的人工智能对话体验。
1 .2 语言模型发展背景
语言模型(Language Model)是自然语言处理领域的核心技术之一,旨在学习自然语言的结构和几率散布。随着深度学习技术的发展,语言模型获得了显著的进步,从最初的基于 n-gram 的统计模型,到基于循环神经网络(RNN)和长短时记忆网络(LSTM)的神经网络模型,再到最近几年来的基于 Transformer 架构的预训练模型,如 BERT、GPT 等。
这里面 RNN(Recurrent Neural Network):循环神经网络 RNN 是一种特殊的神经网络结构,其能够处理不定长的序列输入。RNN 的关键创新在于引入了循环连接,使得网络在处理序列数据时可以保存之前的历史信息。但是,RNN 存在梯度消失和梯度爆炸问题,这使得网络难以学习长距离依赖关系。
所以后面出现一个 LSTM(Long Short-Term Memory):长短时记忆网络 LSTM 是 RNN 的一种变体,专门设计用来解决梯度消失和梯度爆炸问题。LSTM 通过引入门控单元(gating units)和记忆细胞(memory cells),使得网络能够有选择地保存或遗忘历史信息。这使得 LSTM 在处理长距离依赖关系方面表现优越。
后续在 NLP 的发展进程中,一些关键技术的出现推动了语言模型性能的突破。例如,神经网络模型成功解决了 n-gram 模型中数据稀疏性和长距离依赖问题;而 Transformer 架构通过自注意力机制(Self-Attention Mechanism)提高了计算并行性,大幅提升了模型的训练效力。
最近几年来,预训练模型成了自然语言处理领域的核心技术。通过在大范围文本数据上进行无监督预训练,模型可以学习到丰富的语言知识。再结合任务相关的有监督数据进行微调,预训练模型可以在各种自然语言处理任务上获得优良表现。GPT 系列模型作为预训练模型的代表之一,特别在生成任务方面表现突出。
通过上述讲述大家应当理解 RNN、LSTM、BERT、GPT 模型的区分了,就不分析 RNN、LSTM 等模型,以下内容主要以 Transformer 为基础的 BERT、GPT 模型为主。
二、ChatGPT 核心技术
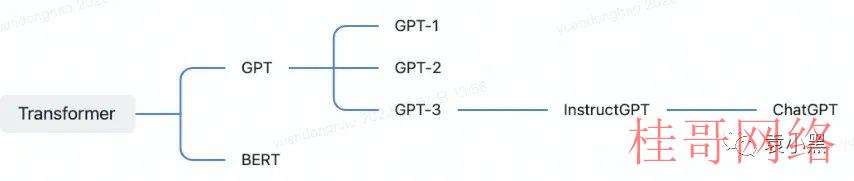
预训练 Transformer 模型主要以 BERT、GPT 模型为主。
2 .1 GPT(Generative Pre-trained Transformer)模型介绍
GPT 是一种生成式预训练 Transformer 模型,由 OpenAI 团队在2018年首次提出。
GPT 模型是一种自然语言处理(NLP)模型,使用多层变换器(Transformer)来预测下一个单词的几率散布,通过训练在大型文本语料库上学习到的语言模式来生成自然语言文本。

GPT 是预训练模型,是基于一些基础模型演化而来的,如 GPT⑵ 是基于 GPT⑴ 之上训练而来,GPT⑶ 是基于 GPT⑵ 而来。随着版本的升级,模型的层数、参数数量和预训练数据范围都在不断增加,从而使GPT在各种任务上获得更好的性能。特别是GPT⑶,其具有超过1750亿个参数,被认为是自然语言处理领域的一项重要突破。
GPT⑶通俗解释: GPT⑶模型是计算机在具有3000亿单词的⽂本语料基础上训练出的具有1750亿参数的模型。这⾥⾯3000亿单词就是训练数据, ⽽1750亿参数就是沉淀下来的 AI 对这个世界的理解,这个理解包括了对⼈的语⾔⽂法的理解,也包括 ⼈类世界的具体知识。ChatGPT 使⽤新训练⽅法调剂了 GPT⑶模型,并将 GPT⑶模型的参数量紧缩了 100多倍,还具有了对话聊天的能⼒。
和以往的AI对话机器人区别的地方:⼀个通⽤超⼤模型尝试解决⼈类世界的各种问题,⽽不是由写 诗模型、写代码模型、写⼴告模型组合起来的⼀个家伙。所以“他”恍如具有了像⼈⼀样的通⽤能 ⼒,并且这个通⽤能⼒在某些⽅⾯还⾜够的好。
GPT⑶.5在2022年11⽉底进⾏了两个更新,分别是 text-davinci-003和 ChatGPT,其中 ChatGPT 以对话情势进⾏交互,既能回答问题也能承认毛病、质疑不正确的条件和谢绝不恰当的要求。
2.2 预训练与微调 (Pre-training and Fine-tuning)
Transformer 的训练分为两个阶段:预训练和微调。在预训练阶段,模型在大量的文本数据上进行无监督学习,以捕捉语言知识。在微调阶段,模型在特定的对话数据集上进行有监督训练,以优化对话生成性能。
BERT 和 GPT 主要的区分是预训练任务方式区别:BERT 的训练目标是通过上下文预测缺失的单词(掩码语言模型),而 GPT 的训练目标是预测给定上文的下一个单词(自回归语言模型)。BERT使用双向Transformer编码器,同时斟酌上下文来学习单词的表示。这使得BERT能够捕捉到更丰富的语义信息。相反,GPT使用单向Transformer解码器,仅根据左边上文来生成下一个单词,这使得GPT在某些需要充分利用上下文信息的任务上可能表现较差。
虽然这篇主要是讲 ChatGPT 背后的原理,但是为了让大家更好地理解:这里会写出 BERT 模型和 GPT 模型的训练区分。
2.3.1 预训练任务 (Pre-training Tasks)
在自然语言处理领域,预训练任务是指在进行特定任务(如文本分类、问答系统等)之前,对模型进行大量无标签数据的训练,使其学会基本的语言知识。预训练任务的目的是为了让模型在以后的下游任务中有更好的性能表现。
BERT 模型训练任务
BERT 主要训练⽅法是做完型填空,在训练进程中对某个词的学习要观测当前词的所有上下⽂更新模型参数,可以认为模型在观测了⼤量⽂本语料以后建 ⽴了每一个词和其他的词之间的关系。
BERT常见的预训练任务包括:掩码语言模型(Masked Language Model, MLM)、下一句预测(Next Sentence Prediction, NSP)等。接下来我们详细介绍这些预训练任务。
1)掩码语言模型(Masked Language Model, MLM)
掩码语言模型是一种以自监督的方式学习句子中辞汇和语法结构的任务。在训练进程中,输入句子的一部份单词会被随机替换成掩码符号(如[MASK])。模型的目标是基于上下文信息预测被掩码的单词。通过这类方式,模型能够学习到句子中的辞汇和语序关系。这有助于模型更好地理解句子的结构和语义信息。
例如,给定句子 "The cat is playing with a toy",MLM 任务可能将其变成 "The [MASK] is playing with a toy",模型需要预测被掩码的单词是 "cat"。
2)下一句预测(Next Sentence Prediction, NSP)
下一句预测任务主要用于模型学习句子间的关系。在训练进程中,模型接收两个句子作为输入,需要预测第二个句子会不会紧跟在第一个句子以后。这样,模型可以学习到句子间的逻辑关系和上下文信息。这有助于模型理解段落和长文本的结构。
以这两个句子为例:"The weather is nice today. I will go for a walk.",模型需要预测这两个句子会不会相邻。在反例中,模型可能接收到的句子为:"The weather is nice today. I had pizza for dinner.",此时模型需要预测这两个句子不是相邻的。
GPT 模型训练任务
⽽GPT的训练⽅向更像是写⼩作⽂,对某⼀个词的预测只依赖当 前词之前的所有⽂本,⽽看不到词以后的内容,所以GPT⼜叫⽂本⽣成模型。
在预训练阶段,GPT 使用大范围的无标签文本数据集进行训练,学习自然语言的一般规律,例如语法、句法、语义和共现信息等。GPT 采取单向自回归语言模型(Autoregressive Language Model),通过最大化给定上文的条件几率来预测下一个词。下面是一个简化的例子:
假定我们有一个文本数据集,其中有一句话:“今每天气很好,我们去公园玩吧。”我们的目标是训练GPT模型能够预测给定上文的下一个词。
1)首先,将文本进行分词处理,将句子拆分成单词序列:["今天", "天气", "很好", ",", "我们", "去", "公园", "玩", "吧", "。"]
2)接下来,根据单词序列生成训练样本,每一个样本包括输入序列(上文)和目标序列(下一个词)。例如:
输入序列:“今天”,目标序列:“天气”
输入序列:“今天 天气”,目标序列:“很好”
输入序列:“今天 天气 很好”,目标序列:“,”
3)使用 Masked Self-Attention 和 Transformer 架构,训练模型根据输入序列预测目标序列。例如,给定输入序列“今每天气很好”,模型的输出应尽量接近目标序列“,”。
4)在全部预训练进程中,模型会不断地调剂参数,以最大化输入序列与目标序列之间的条件几率。这样,当预训练完成后,GPT 模型就可以够捕捉到自然语言中的语法、句法、语义等规律。
需要注意的是,这个例子仅是为了说明GPT预训练阶段的基本进程,实际训练中会在大范围的文本数据集上进行,并且采取更复杂的分词和训练技能。
2.3.2 微调任务 (Fine-tuning Tasks)
在预训练阶段完成后,ChatGPT 需要在特定任务上进行微调,以提高在该任务中的性能。微调是一个有监督学习进程,需要针对特定任务的训练数据集。一些常见的微调任务有:问答任务(Question-Answering, QA)、情感分析(Sentiment Analysis)、文本摘要(Text Summarization)、机器翻译(Machine Translation)、任务导向对话(Task-Oriented Dialogue)。以下以问答任务作为例子:
问答任务(Question-Answering, QA) 在问答任务中,ChatGPT 从给定的上下文中提取答案,以回利用户提出的问题。微调数据集包括问题和对应对案的配对,例如 SQuAD、CoQA 和 QuAC 等。通过在这些数据集上进行微调,ChatGPT 能够提高在问答任务中的准确性和效果。
固然可以。以下是一个问答任务的例子:
假定我们有一段文字作为上下文:
上下文:
《哈利·波特与魔法石》是英国作家J.K.罗琳创作的奇异小说系列的第一部。这部小说的主人公是一个年轻的巫师哈利·波特,他在霍格沃茨魔法学院学习魔法。哈利与他的朋友赫敏·格兰杰和罗恩·韦斯莱一起揭露了魔法石的秘密,禁止了邪恶的伏地魔企图取得永生。
问题:
哈利·波特与魔法石的作者是谁?
预期回答:
J.K.罗琳
在这个问答任务中,输入的问题是“哈利·波特与魔法石的作者是谁?”,ChatGPT 需要从提供的上下文中找到正确的答案。在这个例子中,上下文明确提到了J.K.罗琳是这部小说的作者,因此预期回答是“J.K.罗琳”。通过在问答任务上进行微调,ChatGPT 可以提高在类似场景中准确回答问题的能力。
再以 Huatuo LLMs 的训练数据为例:
{"instruction":"一位年龄在70岁的女性,出现了晕厥、不自主颤抖、情绪不稳等症状,请详细说明其手术医治和术前准备。","input":"","output":"该病需要进行电极导线、脉冲产生器和永久心脏起搏器置入术,并需要使用平静药物和局麻对病人进行手术医治。术前准备包括1⑶天的时间进行术前检查和生活方式的调剂。"}{"instruction":"一个患者的卵巢小细胞癌转移至其它部位,会不会有必要进行手术医治?","input":"","output":"当卵巢小细胞癌转移至其它部位时,手术医治的效果可能不理想,因此一般不推荐进行手术医治。针对转移病灶,可以采取化疗、放疗等医治手段进行综合医治。"}instruction 为指令,input 为背景知识,output 为机器人的回复。
总结:BERT和GPT虽然都是基于Transformer的预训练语言模型,但它们在训练目标、文本处理方式和利用场景上有所区别。BERT重视双向上下文建模,适用于自然语言理解任务;GPT则以生成能力为主,更适用于自然语言生成任务。
2.3 甚么是参数
为何 ChatGPT 或其他大预言模型以参数为量级,衡量大语言会不会优越性等?
在大语言模型中,参数主要是神经网络中的权重和偏置。神经网络由多个层组成,每层包括许多神经元。这些层之间的连接由权重和偏置决定。权重和偏置是模型根据训练数据自动学习并调剂的数值。参数就是神经元之间的连接,即参数就是这些权重和偏置。
所以参数越多,即意味该大预言模型能处理的任务越多。大型语言模型,如 OpenAI 的 GPT⑶,通常具有数千亿个参数。这些参数使得模型能够学习到更丰富的知识和更复杂的模式,从而提高其在各种任务中的表现。但是,大量参数也意味着更高的计算资源和存储需求,和潜伏的过拟合风险。
2 .4 最后基于 GPT 出来的 ChatGPT
ChatGPT 是 Openai 基于 InstustGPT 微调而来。ChatGPT 是具有理解上下文、联贯性等诸多先进特点,有着多种利用场景的**聊天机器人。2022年11⽉30⽇由 OpenAI 发布。

ChatGPT 目前能力范围可以覆盖回答问题、撰写文章、文本摘要、语言翻译和生成计算机代码等任务。
现在看看业界中文的大语言模型排行榜:

排行榜会定期更新,可访问:
https://www.cluebenchmarks.com
https://github.com/CLUEbenchmark/SuperCLUE
三、ChatGPT 的优势与挑战
ChatGPT 的产业链上下游玩家百花齐放

3 .1 优势
3.1.1 强大的语言理解与生成能力
由于 GPT 模型在预训练阶段学习了大量的语言知识,因此 ChatGPT 具有强大的语言理解与生成能力。这使得 ChatGPT 可以更好地理解用户的意图,生成更加准确和丰富的回复。
除基本的语法和句法知识外,ChatGPT 还具有深度的语义理解能力。这意味着它可以在更高层次上理解用户的问题和需求,为用户提供更加精准的回答和建议。
得益于 GPT 模型的强大生成能力,ChatGPT 可以根据用户的问题和场景生成多样化的回答。这不但使得它能够满足用户的个性化需求,还可以为用户提供更加丰富多彩的聊天体验。
ChatGPT 不但适用于聊天场景,还可以利用于其他任务,如文本摘要、问答系统、文本生成等。这意味着它可以为用户提供更加全面的服务,满足用户在区别场景下的需求。
使用 ChatGPT+Prompt 工程,可以快速替换传统的技术学习模型。特别是分类问题。
3.1.2 适应多领域利用
和以往的AI对话机器人区别的地方:⼀个通⽤超⼤模型尝试解决⼈类世界的各种问题,⽽不是由写 诗模型、写代码模型、写⼴告模型组合起来的⼀个家伙。所以“他”恍如具有了像⼈⼀样的通⽤能 ⼒,并且这个通⽤能⼒在某些⽅⾯还⾜够的好。
3.2 挑战
3.2.1 安全性与道德风险
1)ChatGPT 产生的答复会不会产生相应的知识产权?ChatGPT 进行数据发掘和训练的进程会不会需要取得相应的知识产权授权?
2)ChatGPT 是基于统计的语言模型,这一机制致使回答偏差会进而致使虚假信息传播的法律风险,如何下降其虚假信息传播风险?
3.2.2 时效性和一本正经得胡说八道
1)ChatGPT 的回答可能过时,由于其数据库内容只到2021年,对触及2022年以后,或在2022年有变动的问题无能为力
2)ChatGPT 在专业较强的领域没法保证正确率,即便在鸡兔同笼此类低级问题中依然存在毛病,并且英文回答和中文回答存在明显差异化
3)ChatGPT 对不熟习的问题会强行给出一定的答案,即便答案明显毛病,仍然会坚持下去,直到明确戳破其粉饰的内容,会立马道歉,但本质上会在不熟习的领域造成误导
3.2.3 模型运行效力
1)生成的字越多,回复效力越慢。
2)并发量低,费用高。
四、总结
语言模型发展背景:从基于 n-gram 的统计模型到基于 RNN 和 LSTM 的神经网络模型,再到基于 Transformer 架构的预训练模型,如 BERT 和 GPT。
ChatGPT 的核心技术包括:GPT 模型、预训练与微调策略等。GPT 模型利用多层变换器进行自然语言文本生成;预训练阶段在大量文本数据上学习语言知识,微调阶段在特定任务数据集上进行优化。
BERT 和 GPT,它们在训练目标、文本处理方式和利用场景上有所区分。BERT 重视双向上下文建模,适用于自然语言理解任务;GPT 以生成能力为主,适用于自然语言生成任务。
参数主要是神经网络中的权重和偏置,数量越多意味着模型能处理的任务越多,学习到更丰富的知识和更复杂的模式。但大量参数也意味着更高的计算资源和存储需求和潜伏的过拟合风险。
ChatGPT 作为一种基于 GPT 模型的聊天机器人,具有强大的语言理解和生成能力,能够适应多种任务和场景,为用户提供个性化和多样化的回答。随着人工智能技术的不断发展,ChatGPT 将在未来发挥更大的作用,为人们带来更加智能的生活体验。
桂)哥)网)络www.GuIgege.cn
TikTok千粉账号购买:https://www.tiktokfensi.com/
本文来源于chatgptplus账号购买平台,转载请注明出处:https://chatgpt.guigege.cn/jiaocheng/29188.html 咨询请加VX:muhuanidc
